I love Creative Commons, ok? I’ve followed, used, the licenses since the start, I have the t-shirts. And like many, I can rattle of the stack of letters and explain them.
But in my internet roaming, especially for my other strong interest, photography, I come across things in practice, well, that are much less cut and dry. Like a few posts ago when I fell into some slimy and weird toy spaces of public domain (not strictly CC, but in the same neighbourhood).
And I also love cacti. They are unworldly, especially to an east coast born suburban kid (well I did taste the Southwest through Roadrunner cartoons), but so intriguing in design and beauty that defies the probably of life with almost no water.
Both seem simple from afar, yet different up close, and occasionally you might get stuck by a sharp spine.
Have I exhausted the un-necessary metaphor? I can’t resist, this was my photo I found my searching my flickr stream on “details”.
On with the show.
Old man internet warning- this started while reading my RSS feeds in my folder of Photography sites. I clicked to read the PetaPixel article Generative AI is a Minefield for Copyright Law. Of course it opens with the requisite surreal AI generated image, but frankly does not really give me anything new beyond what I’ve read before– especially from those great CC folks. Bottom line, no one can really say for sure where the clear rules and guidelines will land on generative imagery. It’s messy. Again.
But this is where it got me curious. Down at the credits bottom of the PetaPixel article it reads:
The opinions expressed in this article are solely those of the author. This article was originally published at The Conversation and is being republished under a Creative Commons license.
https://petapixel.com/2023/06/18/generative-ai-is-a-minefield-for-copyright-law/
It is “being republished under a Creative Commons license”. What license is “a”? And where is the link to the license? I am an observer of attribution practice, and this one falls way short of the Creative Commons Best Practices. Okay, that’s just being sloppy. I am no perfectionist.
But I am curious.
I follow the one link to the original article published at The Conversation (I have read many great articles there, good writing happens, I declare). What’s curious here is I can find no mention of a Creative Commons license on the article. There is a footer assertion "Copyright © 2010–2023, Academic Journalism Society" — so I did around for more.
Not that it would ever be clear to look for license details under a link for “Republishing Guidelines” there it is.
We believe in the free flow of information and so publish under a Creative Commons — Attribution/No derivatives license. This means you can republish our articles online or in print for free, provided you follow these guidelines:
https://theconversation.com/ca/republishing-guidelines
The belief in free flow of information is a nice sentiment. And there is is, they are asserting a CC BY-ND license across their publications. One license to rule them all.
Except.
The conditions.
Now this was somewhat new to me, but I heard the smart and esteemed Jonathan Poritz (certified facilitator of the Creative Commons Certificate) say in an online license quibble that adding extra conditions to a CC license… nullifies it (?) That seems to be clear on the response on the CC Wiki to the question “What if I want to add some conditions and I clarify what I mean by a specific term? Is there anything wrong with adding conditions on top of a CC license?” though the details written under License Modification fall into the Ask a Lawyer region.
Back to the conditions on The Conversation’s site- the first three seem to be the scope of the CC BY-ND license: “You can’t edit our material” (that’s ND), “You have to credit authors and their institutions” (that’s attribution), “You have to credit The Conversation and include a link back to either our home page or the article URL” (also mostly standard attribution).
The question to be is the next one:
You must use our page view counter when republishing online. The page view counter is a 1 pixel by 1 pixel invisible image that allows us and our authors to know when and where content is republished.
https://theconversation.com/ca/republishing-guidelines
Can they really make that a condition of reuse? To deploy a tracking pixel?
That smells a bit weird to me, along with there being no clear indication of the CC ND license directly on articles (hence why PetaPixel does not know what license to declare??).
Okay, this is truly quibbling, but thinking about these details is important, more than just a simple pat acceptance of the basic rules of licensing.
For a recently published post I sought an image of a well known brand of candy– it’s not surprising of course that there are not many available- funny in that my google image search filtered for CC licensed results, a high ranking one was my own flickr photo of the spanish language version I spotted in Mexico (and likely that might be a copyright infringement, shhhh).
The one I liked (and used) was pointed from Google to rawpixel. There’s a great image! But zoom in close, and there’s some fishy things happening.
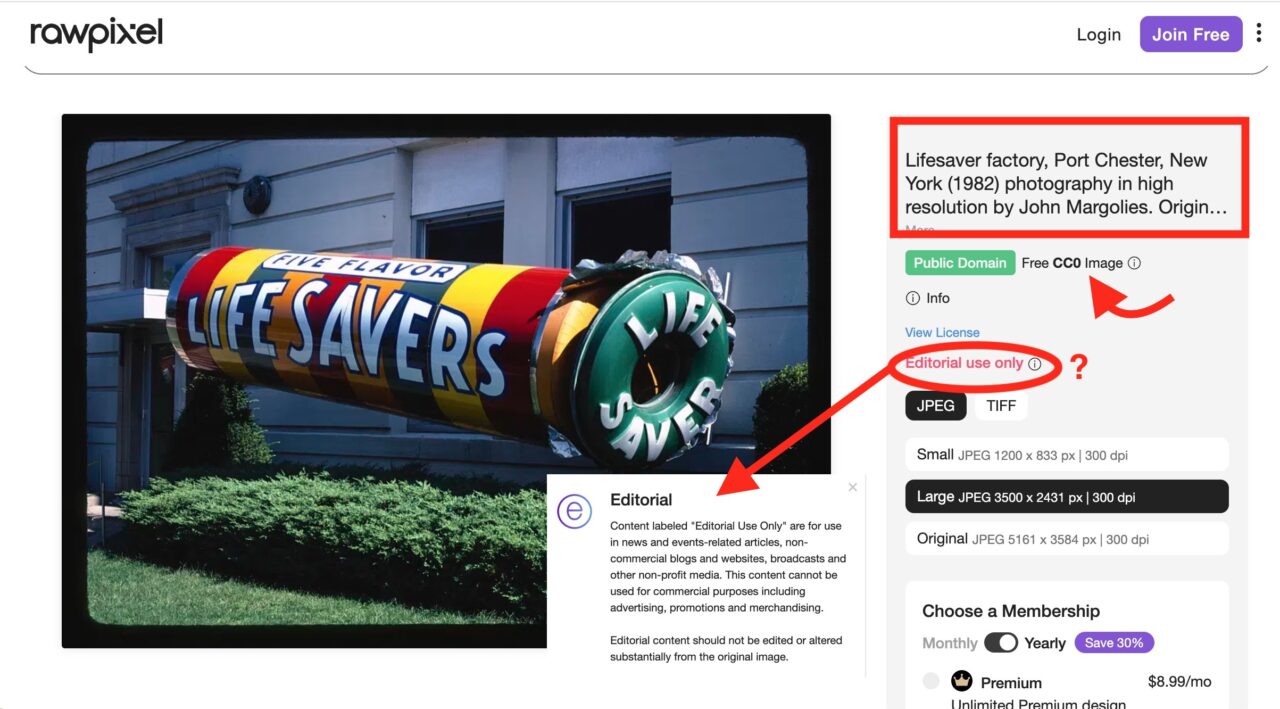
I am very familiar with the iconic roadside Americana photos of John Margolies, readily available public domain content from the Library of Congress.
Rawpixel does declare the image source (not linked) and the CC0 license. All kosher. So far.
But try to download the image- you are required to create an account. Even free, why do I have to sign up for an account to access public domain content (hint, the upsell answer is in the lower right corner). So rawpixel is repackaging public domain content but putting a requirement to download.
I can right control click and download easily (I did) and that trick of hiding images in a .webp file format is no barrier (Preview on OSX now converts it easily to JPEG).
But there’s more. What is that Editorial Use Only link, right below the link to the CCO license?
Content labeled “Editorial Use Only” are for use in news and events-related articles, non-commercial blogs and websites, broadcasts and other non-profit media. This content cannot be used for commercial purposes including advertising, promotions and merchandising.
Editorial content should not be edited or altered substantially from the original image.
rawpixel.com
Now wait a minute- how can Rawpixel put extra conditions on CC0 content? I’d say this is enforceable as wet tissue.
Compare this to the source of this same image at the Library of Congress. No logins required, the images are directly there in usable JPEG format, and there are no extra conditions.
The question is- why does Google give preference in search results to fishy re-packagers of public domain content over the actual source?
We all know the an$wer.
You should. When we just grab stuff because some web site says its free, us, especially as educators, should be looking at the fine detail. The same is true for the inevitable world changing tsunamic technofad (look closely at the top results, outside of Wikipedia, is there a pattern?).
Again it’s something at a quick glance has a statistically valid appearance of resembling useful information. If you grab and go, because it’s done for you easily, do you understand/question what you got? Can you zoom in and get an understanding of how it works, where it gets its info from? Can you even view source?
Nice pretty cactus there.
Featured Image: My photo! CCO, natch!

For perhaps the first half of my Type-1 diabetic life (October marks 53 years without a properly functioning pancreas) I invariably walked around with a roll of these in my pocket.

Yes, it did take some explanation to other school kids when suddenly I started shoving them in my mouth “Hey! You’re diabetic, you can’t eat sugar”. In short the need to inject the insulin most of your bodies manufacture as needed in the right amounts means a diabetic lives in a blood sugar level roller coaster, zooming too high and plummeting too low.
The brand name of these candies are literally true (I was tickled to find them with a translated name while working in Mexico).

Over time, in the moist heat of Baltimore summers, the candy rolls often got fused, or the labels cemented to the candy, all adding to that urgency when a “low” snuck up unexpectedly.
There was this time when my high school friends and I decided to skip school and go out on a river raft trip down the Youghiogheny River. Only Jimmy had ever rafted before. And we did not know that the day we went was the day of an upstream dam release. It’s one of those “lucky we survived” high school tales, but also, I felt those waves of weakness creep up on the last stretch as we floated victoriously into Friendsvill, MD. I reached in my pocket, and found a plastic bag with my candy, mangled, half melted, but again they lived up to their name– life saved again, by candy.
Fast forward to adulthood- I forget when, 20 years ago? I discovered glucose tablets as a better treatment. More effective in the time to raise blood sugars, they came in little plastic tubes, more durable, and I could buy replacements in more economical sized containers. They were not quite as tasy, but worked better

I purchased them over the counter at the drug store and big box discount store I will not name, but I kept bottles in drawers, vehicles, camping supplies. I started ordering them along with my OmniPod (insulin pump) replacements.
Sometime in the last year, they started not being available from my online supplier, The shelf at the pharmacies were empty, as was the W mart store. Strange. I went to ye olde trusty Amazon, but the only listings available were at like 5 times the normal price and only from suppliers in the UK.
What happened to the Dex-4 tablets in Canada? Having some research skills and tools, I got to the manufacturer page at https://www.dex4.ca/

The cryptic message in French here has not changed in months. No explantion (the English is just a scroll down):
We are temporarily experiencing inventory shortages.
We know how much you count on Dex4. We also want you to know that you, our customers, are our #1 priority and we are working diligently to get products back on your pharmacy shelf as soon as we can.
We apologize for this inconvenience. Should you have questions, please contact customer service at
https://www.dex4.ca/
1-800-363-2381 Monday- Friday between 8:30AM-5:00PM ET.
No explanation. I looked for news of Dex4 Shortages in Canada but only found references to shortages of dextrose for emergency responders. I did dive into reddit zone (before the current meltdown so this is from memory) and found speculations that it was something controlled by Pfizer. Some dude in Toronto claimed he was getting them off the shelf at local stores. Other wild guesses it was because of a label gaffe that it was not translated into French (not true I have the bottles and besides look at their website).
My local pharmacist has no explanation either. So I am left to only speculative fantasies of conspiracy… the mystery is out there, what happened to the glucose tablet supply in Canada?
I recently bought a bag of my old favorite, but was rather disappointed in this kind of wasteful and time consuming packaging.

Maybe someone else out there has better sleuthing skills. Until an answer comes or they appear on shelves, I am back to plastic bags of candy.
What happened to the Dex4 supply in Canada?
Featured Image: I could use a large roll of these!

webp image format displayed will not prevent me from downloading directly and converting!Oi. My clever blog post title generator is not really jelling this morning (the unArtificial quasiIntelligence needs more coffee).
The VHS tape for #ReclaimOpen 2023 has reached the end spool, and people are dusting their blogs off to reflect on the tri-part questions of the Open Web: How We Got There, Where We Are, and We Could Go. I was not on the ground there and only caught bits on reruns (apparently my generated spawn crashed the scene).
From Jon Udell’s post in Mastodon, I was invigorated by Mo Pelzel’s thoughts on Whence and Whither the Web: Some Thoughts on Reclaim Open, e.g.
…when it comes to appreciating the sheer magic of the hyperlink. To this day I have not lost the sense of wonder about this marvelous invention.
https://morrispelzel.com/uncategorized/whence-and-whither-the-web-some-thoughts-on-reclaim-open/
and teaching me the wonderful concept of anamnesis, — “refers to ‘making present again,’ or experiencing the meaning of past events as being fully present.”
This circles back to something that has been floating as a write worthy topic, and how delightful it is to upend and bend around what you thinks is right. Let a new tape roll.
Ages ago (months) amongst noticing the drying up of colleagues blog posts in my reader and noticing how many were sharing their content in the various social spaces, I was bit taken back. Many resources I saw being created, activities, collections of things, that I typically would have thought people would publish as good ole durable web pages or something in a blog powered platform– were, arggh, shared as Google Docs.
Docs.
Don’t get me wrong, I love me the use of the shared document. But really, it is the marginal evolution of the Word Processor. I know why people reach for them – it’s easy to use (who wants to WRITE HTML??) (me), it publishes to the web, and its the environment their work places them for large chunks of the day.
Yet, the creation of doc hosted web pages rings of “being on the web but not of the web” (Have you ever done view source on a Google doc?, can you really grasp the content and meaning it’s un-HTML a melange of JavaScript?). Here’s some beef:
https://docs.google.com/document/d/1pGhX4uWZLJYsyo78nAydlZQ10Z8rBT-QutlYZXugly4U/edit?usp=sharing You cannot even foresee what the link leads to from its URL, not its source (e.g. a domain name) nor any kind of file name that suggests its relevant. I thought I had more. But when I think of the Open Web as the place of where we “got there”, is a Web of Documents really going to be anything more than a google sized pile of free floating papers, only findable by… its search? Is this just on the web but not very web like in spirit?
Yeah, I did not really have well developed case there, just some disgruntlement and seeing an increasing abandonment of creating web content as the kind of web content I know and love, the kind you can inspect as source and learn something or understand how it is constructed.
Hence the blog post never congealed.
I did a complete turn around on my chewing of sour web games when I stumbled across this piece on The Doc Web, published in some thing called “Lens” (c.f. the web as an infinite space that seems to be boundless), even filed in a section called Escape the Algorithm “Remote corners of the internet—through the eyes of its finest explorers” That speaks to me as a rabbit holer.
This article completely undermined my so called “beef”
?No one would mistake a word processor for the front page of the internet, not unless their computer is nothing more than a typewriter. A hammer is not a portal, and Google Docs, the word processor of our time, is nothing more than a hammer to the nail of language. Right?
https://lensmag.xyz/story/the-doc-web
Slow down. Google Docs may wear the clothing of a tool, but their affordances teem over, making them so much more. After all, you’re reading this doc right now, and as far as I know I’m not using a typewriter, and you’re not looking over my shoulder. This doc is public, and so are countless others. These public docs are web pages, but only barely — difficult to find, not optimized for shareability, lacking prestige. But they form an impossibly large dark web, a web that is dark not as a result of overt obfuscation but because of a softer approach to publishing. I call this space the “doc web,” and these are its axioms.
It’s Axioms knock down my disdain bit by bit. What I saw as a negative in the obfuscation of the web address at foretelling its content, hits on the magic of storytelling, with the element of surprise. An invitation to explore without knowing what’s ahead. And it really range true with the fantastic linked list of examples in Axiom 5, where it shows you the fantastic ways some utterly creative souls have subverted the usual “documentness” of the way 99.9% of use use Google Docs (like ye olde Word Processor) and have created some insanely enjoyable web corners.
Just glance:

I leave it for you to discover, but these are mind blowing examples of web ingenuity subverting the document concept:
I love this kind of stuff. This shows that despite the age of our algorithmic AI wielding web T-Rex’s, there are all kinds of creative mammal scurrying around in the web underbrush.
I can dig this Web of Docs.
Speaking of the web that was- we always talked about the web as “pages” (skeuomorphing as much as “dialing” a phone) — the construct of them with formatting “tags” is very much taken from the old document producing methods that pre-date the web.
And smack my own head in memories- it very much was the need for “publishing” documents in a shared format got me on the web in 1993. In my work then at the central faculty development office at the Maricopa Community Colleges, I was eager to provide across our large system means for people to yes, share resources, but also, our published journal which had been going out in campus mail on paper.
I was driven then to find digital ways to share so much information I saw in paper. And while we had a system wide shared AppleTalk network for mac users, half of the system was on Windows PCs. Until late 1993, I had been making a lot of effort to make resources available on a Gopher server (a Mac II plugged into the network).
I went through some extraordinary (and laborious) efforts once to publish our journal as a HypeCard stack and convert it with some app to Toolbook (which ran on windows). It worked… but was really ugly to do.
In that time I had come across the early text based World Wide Web (as it had to be said them) browsers, you’d have to enter a number on a command line to follow a hyperlink, and most of what I saw was papers of some physics lab in Switzerland. It was not “clicking” yet.
Then, like many lightning bolts I had, a wise figure intervened. In October 1993 I was visiting Phoenix College for a tech showcase event, and a great colleague named Jim Walters, very wizard like, handing me a floppy disc upon which he had written “MOSAIC”. All he said was, “Hey Alan, you like the internet, try this.”
This was always a powerful lesson- Jim was not trying to techsplain to me or show off his vast experience, he handed me an invitation to explore. He made a judgement call that this might be of interest.
That of course changed everything. That the web was navigable in this first visual web browser my clicking links, and it included images, even crude audio/video, was a mind opener. And then when I came across the NCSA Guide to HTML. I saw that with a simple text editor, I could create rich media content, that could be connected to other places with this magic href tags– and best of all, it was in a format that both Mac and PC computers could navigate the same content.
In about two weeks of getting that floppy disc, I came across software that would let me run a public web server from a Mac SE/30 plugged into an ethernet port on my office, and I was off on this journey.
And the bigger light was, yes, I had some know how to set up a web server, but the fact that web pages crafted in HTML could actually be shared on floppy discs or local media, meant that I could help faculty learn to create their own web media documents, etc, becoming maybe my first somewhat successful web project beyond my institution, Writing HTML.
And that still rings to me, here 30 years after my first web server, that the act of writing the web, not just clicking buttons in an interface, or at least conceptually understanding how the href tag works, is the magic light in all the mix.
The very fact, that through mostly a tactile act of writing a tag, I can create a linked connection from my blog here, to say Mo’s post is completely what the open web was and still is about.
The link. And Writing Links is an act of generosity for both the linkee and the reader.
A web of Documents or the Doc Web? It does not matter, it’s all webbed.
Featured Image:

I sure miss the days of supporting the H5P Kitchen project — if anything really hits the elements of the olde 5 Rs, to me, it’s the portability, platform independence, downloadability, reusability of H5P plus, the thing fe really love, built in metadata.
So when I spotted a reshare of this University Affairs online article on ChatGPT? We need to talk about LLMs my interest was in the writing — and it is a worthy read about getting beyond the AI inevitability to how we grapple with the murk of ethics.
But here is what jumped out to me in the middle of the article– OMG it’s H5P! I can from a kilometer away that’s what it is, an Interactive Hotspot Diagram.

Typical of H5P, this has a Reuse button (so you could download the .h5p source), an Embed code button (I could have inserted it here in my blog), but ones is missing… The one labeled “rights” which is actually the item’s metadata. You see, there is nothing that identifies the author of this content or how it is licensed — well until I squinted, in the image itself is © REBECCA SWEETMAN 2023. So what we have here are a fraction of the 5Rs.
Metadata, metadata, rarely loved or appreciated beyond librarians, archivists, data nerds. In the H5P Kitchen I wrote a guide to why/how this is used:
But I was curious about that LLM Hotspot, and it was 15 seconds of a web search on the title and adding “H5P” that got me to a source, of course, in the eCampusOntario H5P Studio— where we at least see the author credit, but alas, it was shared without specifying a license. Oh, I could have gotten there faster if I inspected the embed code the source is in the URL.
This is minor quibbling of course. I was tickled to see an interactive document in a web article. It’s just so close to making the best use of tools, but as the word “virtual” goes, it’s always “almost there”.
Featured Image:

Google Docs will have it, Microsoft is brewing it, PhotoShop is doing it, so is zoom…it’s high time that the advanced technology of CogDogBlog hop on the artificial intelligence inevitable train.
As demonstrated this week at the Reclaim Open 2023 conference, behold the new generation of blogging powered by AI Levine:
This is all the mad creativity of Michael Branson Smith, who along with Jim Groom (he has a blog, right?) contacted me a few months ago with a request for a short video he could us to train some AI that would generate some manifestation of me as a speaker at the conference.
How could I refuse? Michael is one of he most creative and gracious people I have gotten to know in this ed tech game, initially through DS106, but hey we have spent time together hanging out at his home in Brooklyn.
Michael shared a few prototypes, all of them definitely weird with artifacts, but still sounding like me. Each time he asked if I was okay with it, I said I trust you completely, MBS, do as you see interesting.
I did not travel to Reclaim, but enjoyed the online perch for the conference (I have to say that the Reclaim Hosting set up for live streams is one of the best I have seen. Live streams are viewed adjacent to a Discord chat, with its TV Guide like directory guide at the top.
Michael shared some details of his intent to learn something about AI by doing it himself (DS106 spirit showing). I am forgetting the tools used (it’s in the video and hopefully a future MBS blog post). The original video I sent did not perform well, so MIchael relied on one from the YouTube I recorded in 2019 as an intro to students at a Coventry University class I was doing something with. Meet AI Levine’s puppet:
Michael did say generating the AI audio was the bigger challenge- i believe he used ElevenLabs for text to speech. AI Levine’s blabbering was based on a ChaGPT query to talk about SPLOTs derived from 4 blog URLs MIchael gave it to chew on. The “hallucinating” is readily apparent in the history portion but the gist of it is maybe palpable.
As was obvious to most in the room, the video generated was weirdest with the mouth, and Michael ended up blurring AI Levine a bit in post editing.
In emails the day or two before, Jim Groom suggested some kind of irate outburst from me in chat where they could then bring me in to the room (via a whereby.com link). That would be fun, and of course, anyone ought to get bent out of shape by being deep faked. That’s too easy.
My play was then to act dismissive, to assert that I am actually a supreme AI construct:
For a long time I have been “training” myself by reading the entire internet. Everything I have made, written, created was generated from a complex process applied to this data. SPLOTs could only have been generated this way.
(no idea if this is what I actually said)
All in all it was quite enjoyable, as was seeing on the live stream and the whereby video much different views. All surreal.
Thanks Michael for creating this fallible facsimile in every AI sense of hallucinatory mockery and thanks Reclaim Hosting for putting this on the program.
For me, this again, puts on the table some impressive technical feats to produce, well the equivalent of flavorless mind porridge. Generative content stays within the guardrails of statistic probability yielding an appearance of pseudo meaning. Downtown Dullsville.
What I’ve not seen AI do is to make meaning and connections between the unlikely related. For example, in my regular training on internet content (aka reading blogs), my own neural pathways ran off in different directions in Martin Weller’s fab post Yankee Shed Foxtrot where he weaves also different, seemingly unrelated topics- a book on “shedworking” and a song by Wilco.
Reading this as a human means I do not regurgitate sentences based on some vectors of word probability. For me and my [Un]Artificial [questionable] Intelligence, a series of other un stochastic connections. My comment on Martin’s blog was one of those that really should have been a post here…. so I will steal my ow words:
What you demonstrate in action here, oh ye faithful blogger, is something AI can’t- make connections between ideas and things that are statistically out of range. Yes, we have neural networks in our grey matter, but the computerized ones that borrow the name cannot (well Stephen will assert its eventually possible) to connect this way.
What foir me your post does is trigger other connections. The idea of “shedworking” (the name new but the idea resonates) for some reason reminds me of a book Scott Leslie recommended (see how connections, work, I can remember it was on a camping trip where we canoed to an island in BC) a book called “Shop Class as Soulcraft” http://www.matthewbcrawford.com/new-page-1-1-2 that honors the value of work we do with our hands, it need not be mechanical, or done in a shed, but is a testimonial to the ideal of craftspersonship and what it does for us (I can extend it to creating web pages by hand).
As far as an academic metaphor (you are cornering the market!) I love the idea of conceptually makeing space and time for crafting. And yes, institutions are not providing this per se, but there is a two way play here- us as individuals have some responsibility for also not making the time and place ourselves for doing this. People who design their shedworking places are not just given them by an organizational entity, they take it on themselves. We as individuals have a stake in this.
And then for the music metaphor, I dont know if you are into the Song Exploder podcast https://songexploder.net/ It’s a brilliant concept where musicians break down a finished song into its origin story, how the tracks came together, layer by layer. It’s a fabulous metaphor (to me) of what we do little of in our work (outside thr last ferw bloggers standing) of not just pumping their finished work, but the craft of how it was made, how it emerged, if you will from their audio workshed.
I wanted to launch an idea like “Course Exploder” where educators could break down a lesson or a OER or course design in the same way.
What I enjoy about Sound Exploder is that I get these stories for songs and genres I never listen to (sort of like how university requirements had me take courses I would have never chosen on my own interests). I was just listening to the episode where Seal talked about the evolution of the mega pop hit “Kissed by the Wind” (heard the song plenty but cant say its in my listening queue). It’s rivetting to hear him talk about its origin, but there is a bit in the opening where he talks bout his start before being a mega star:
“I was living in a squat. I didn’t have any money and I was just basically getting my act together, trying to figure out who I was musically. And “Kiss From A Rose” came out of that period, when you sort of do things not for any other purpose than because that’s what’s coming out of you. I had no experience in the studio, in a proper recording studio, at that point.”
It’s that line– “when you sort of do things not for any other purpose than because that’s what’s coming out of you” that connects in my head back to Shopcraft and sheds and why we even bother trying to do stuff.
My comment on Martin Weller’s Yankee Shed Foxtrot blog post
I may be on the far end of the bell curve of what people want from the world these days, but I crave more the intelligence that makes meaning from dissimilar ideas, not just spitting back the statistically relevant blandchastic stuff.
You heard it all from me, the always A.I. Levine.
Featured Image: Combination of one frame from the Reclaim Open 2023 presentation The SPLOT Revolution will be Artificial with a conference logo and a SPLOT logo, call the whole thing CC BY.

I was trolling the olde blog settings for the WordPress Jetpack plugin and spotted something that confirmed I had aleady learned– the nuking of Twitter’s API meant the Social module could no longer tweet new posts.
Old news.
But what I did see was a new option to connect my WordPress blog to publish new posts to Mastodon. In like 10 second I connected to my instance and connected my account to this here blog.
Thus, this post is mostly a test of the connection (for which I spent more than too much time in Photoshop on the fetured image).
This might end up double tooting, since I have been using an IFTTT applet to share to mastodon whenever there is a new post in my RSS feed.
Ok, let’s see how this elephant flies with a new Jetpack!
Dead bird dead bird.
I’m no super billionaire businessman, but to cut off the world’s largest web publishing platform from adding content to your product is— dumb ass to the nth degree.
Toot, toot, someone sweep the dead bird off the road.
I have two mastodon post tooters in operation now… for comparison:
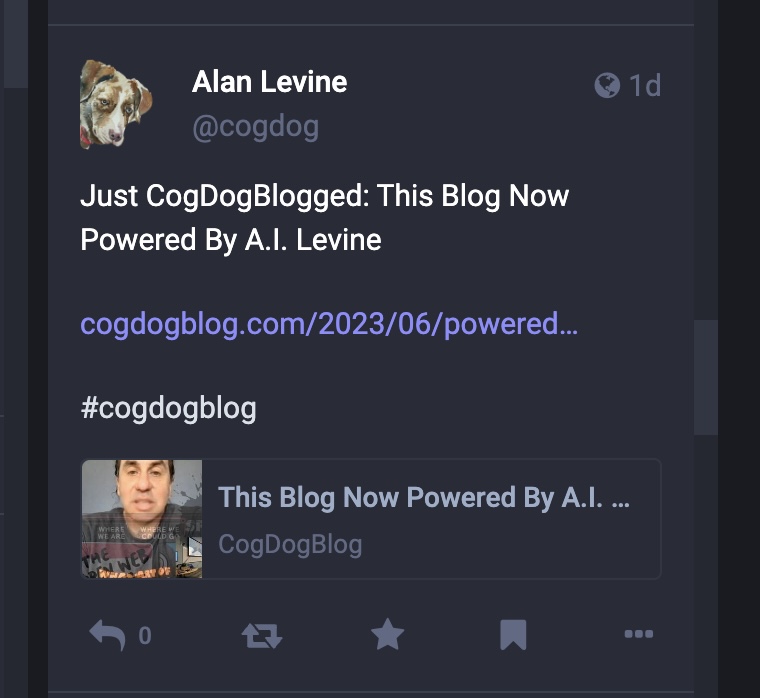

The difference is minor- the Jetpack on includes an excerpt of the post. I like in IFTTT I can customize it with extra text like before the title “Just CogDogBlogged” and adding an extra hashtag. I could include the excerpt in IFTTT but am not sure it matters. Also, IFTTT is a bit delayed, the JetPack one is instant. As if I am that important that I don’t want to keep my fan waiting.
I don’t think it means a hill of beans to anyone except me. I like IFTTT more, but I can use JetPack if the former ever poops out.
Featured Image: My own photoppery (OMG the crap DALL-E gave me for “An elephant wearing a jetpack hovers in the air over a dead bird laying on the road, cartoon style”) based on p1210759 flickr photo by generalising shared under a Creative Commons (BY-SA) license and Dead bird flickr photo by indoloony shared under a Creative Commons (BY-NC-ND) license

People still read blogs. Well, maybe a few of them. I was happy to see others get intrigued and interested in my sharing of the ways Descript had really revolutionized my way of creating podcast audio.
More than likes and reposts there’s not much more positive effect when you can capture Jon Udell’s interest as it happened in Mastodon and as he shared (aka blogged) about an IT Conversations episode he re-published.
And as it often happens, Jon’s example showed me a portion of a software that I was unaware of. This was as I remember one of the most evident aspects I found in the 1990s when I started using this software called PhotoShop- each little bit I learned made me realize how little of it’s total potential I did not know, like it was infinite software.
You see, I made use of Descript to much more efficiently edit my OEG Voices podcasts – but my flow was exporting audio and posting to my WordPress powered site. Jon’s post pointed to an interesting aspect when audio was published to a Descript.com sharable link.
Start with my most recent episode, published to our site, with audio embedded, a link to the transcript Descript creates.
If you access the episode via the shared link to Descript, when you click the play button in the lower left, the transcript highlights each word, in a kind of read along fashion. That’s nifty, because you might want to stop to perhaps copy a sentence, or look something up.

Even more interestingly, you can highlight a portion of text, use a contextual menu, and provide a direct link to that portion of audio. Woah. Try this link to hear/read Sarah’s intro from the screenshot above.
Yes, Descript provides addressable links to portions of audio (note, I have found that Descript is not jumping down to the location, maybe that’s my set up, I did post a request in their Discord bug report).
But wait there’s more. You can also add comments (perhaps annotation style) to portions of he transcript/audio.
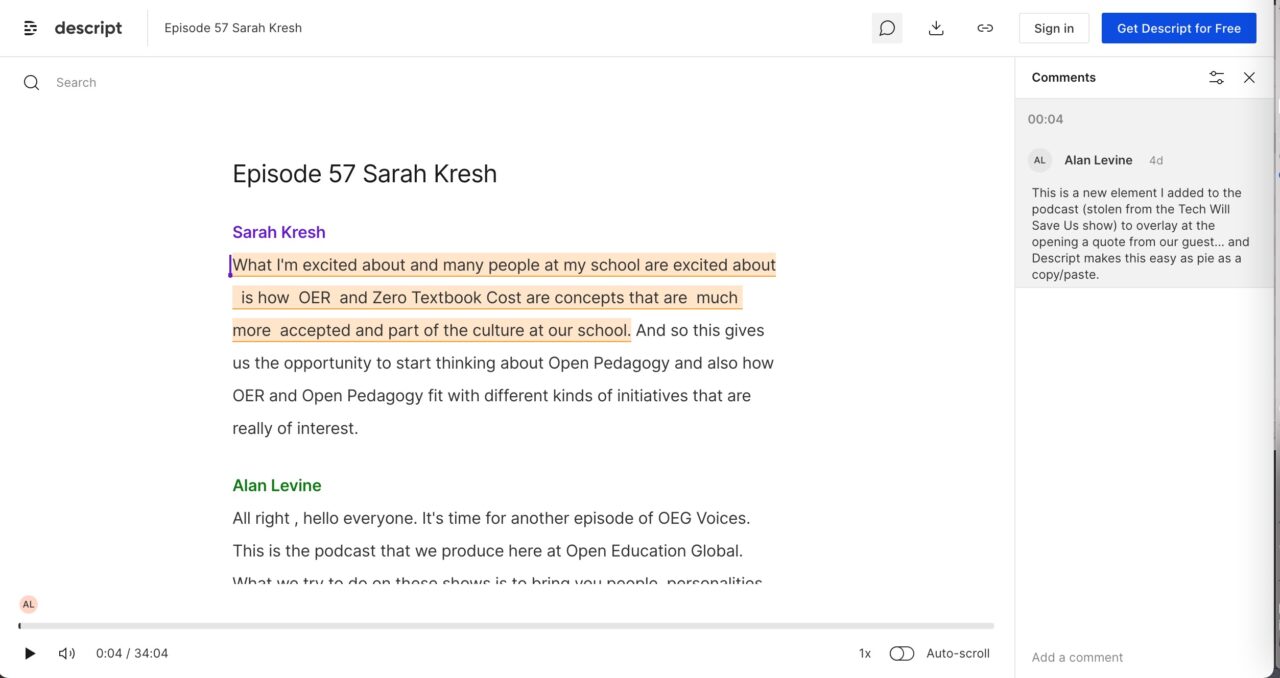
You do have to create an account to comment, so you might not appreciate that. It looks like it’s more aimed at comments for production notes, but why cannot it be more annotation like?
Anyhow, this was nifty to discover, and I would not have known this, had not Jon shared his own efforts with a link.
This is how the web works, well my web works this way. And refreshing to explore some technology and not with the din of AI doomsday or salvation day reverb (although there is a use of AI for Descript in transcription, but it’s at a functional use level, not a shove it your face level).
I am confident as always there is more here that I do not know with Descript than what I do know (I need learn the Over Dub tool).
Featured Image: There’s always that one thing…

It’s about five days since a key date but, there is, after all, something about the fives. Get ready, here it comes.
Yes, one of 365 blocks on the calendar is rather key here at Ursa Acres…

Five years ago was when Cori and I “did a thing” and tied our lives forever together on the porch of a special cottage in East End, Saskatchewan. There were roses when She Said Yes on a visit to me then in Arizona.

As there was five days ago when we celebrated with a fancy dinner at Moose Jaw’s Grant Hall. As most things go we find our spirit more here at our home.

That sure feeling of our fit when we started is even stronger, more deep, and more wonderful today. From Mogollon Rim tied to the Canada Prairie, chasing light and dreams together. Five days later (it’s even better!) it does deserve noting, posting, sharing here amidst our crazy list of things we are doing in June. That is just one of the long list of “whys”.
I love our life, darling, know it, and how we are pursuing our natural landscape remaking here on our acres, with long grass, a future forest plus foxes, geese, deer, grouse, coyotes, frogs, rare cougar, eagle, owl, ravens, and those deep, long, and vibrant skies.
Five and five and more, forever,
Featured Image: A combination of my own photos of five roses and the five cupcake card atop of vow mugs as always openly shared just because that’s what we both do.

While there is plenty of academics undergarment wadding over AI generative text (and please stop referring to it all as ChatGPT), I was first interested and still in the generation of images (a year ago Craiyon was the leading edge, now it looks like a sad nub of burnt sienna).
Get ready for everything to get upturned with Adobe Photoshop’s Generative Fill, now in beta. I spotted it and some jaw dropping examples in PetaPixel’s Photoshop’s New ‘Generative Fill’ Uses AI to Expand or Change Photos but was drawn in more by a followup post on So, Who Owns a Photo Expanded by Adobe Generative Fill? This gets into even more muddy, messy, and also interesting (time curse like?) waters.
That latter article has some really fabulous pieces of ?? Extended Album Covers found originally in the twitter stream of Alexander Dobrokotov. I’d post the tweets here for you to see, but twitter broke the capabilty to embed tweets.
The concept is rather DS106-ish a central image of an actual album cover is embedded into a much larger imagined scene (see the Petapixel post for the examples) where all the imagery around was created with this new Adobe Photoshop beta feature.
I have seen this many times with AI, you see these jaw dropping examples that imply someone just typed a phrase in a box, clicked the magic bean button, and it popped out. Most of the time, if you can find where the “making” of is shared, you will find it took hours of prompt bashing and more likely, extra post processing in regular Photoshop.
Hence why my attempts usually look awful (?)
Now I could just share say image (like the Katy Perry cover of her sleeping in soft material that turns out to be a giant cat) and say, this is cool! But I always want to try things myself. So I downloaded (overnight) the beta version of Photoshop.
The way it works is you use the crop tool to create space around a source image. This fills with just white. But then you select all that blank space along with an edge portion of the seed photo, and watch something emerge. In many ways it’s impressive.
I started with my iconic Felix photo, the one I took on his first days with me in 2016, the one I use often as an icon.

In Photoshop Beta, I enlarged the Canvas to the left a lot, and a little above, and let the magic go to work. Perhaps this is not the best example, since my truck in the background is blurred from depth of field effect.
Not quite magic.

That’s a rather awkward vehicle there. And since AI has no concept of a porch rail, it would likely extend those posts Felix is peeking through into the stratosphere.
I decided to try again, and added a prompt to the generative gizmo saying “Red truck towing a camper”

Well, that looks awkwarder too. But it generates something.
I took another stab, thinking how it might take on extending a wide landscape that is well known. This is tricky because if one knows something of Geology, they canyon to either side extends to a broad plateau.

I did one first where I went about 50% wider on each side

It certainly continues the pattern, and is not all that weird. You do get 3 variations, this one is about the same:

It’s odd, but not really too far from pseudo reality. I riffed off of this version, adding again another chunk of empty space on either side. Now its getting the geology pretty messed up and messy.

These are just quick plays, and there are also the other features in the mix to add and remove elements.
This definitely is going to change up a lot things for photographers and digital artist, and what is real and what is generated is getting so inter-tangled that thinking you can separate them is as wise as teetering off that canyon edge.
But getting back to the Petapixel leading headline, “So, Who Owns a Photo Expanded by Adobe Generative Fill?” oh my is ownership, copyright, and licensing going to get mashed up too. So all of those creative album cover expansions? It’s starting with copyrighted material. But the algorithmic extension, is that so far changed to raise a fair use flag? Heck, I have no idea.
At least if you start with an open license image, you stand on slightly less squishy ground.
I’m going back to my shed to tinker (that’s for Martin).
Featured Image: 100% free of AI!

You know you’ve been around this game a grey haired time if you remember that podcasting had something to do with this thing called RSS. I found shreds of workshops I did back at Maricopa in 2006 “Podcasting, Schmodcasting…. What’s All the Hype?” and smiled I was using this web audio tool called Odeo who’s founder went on to lay a few technical bird droppings.
I digress.
This post is about a radical change in my technical tool kit, relearning what I was pretty damned comfortable doing, and to a medium degree, appreciating for a refreshing change, something that Artificial Intelligence probably has a hand in. Not magically transforming, but helping.
I’ve had this post in my brain draft for a while, but there is a timely nature, since this coming Friday I am hosting for OE Global a new series I have been getting off the grind, OEG Live, which is a live streamed, unstructured, open conversation about open education and some tech stuff… really the format is gather some interesting people and just let them talk together. Live.
This week’s show came as a spin off from a conversation in our OEG Connect community starting with a request for ideas about creating Audiobook versions of OER content but went down a path that including interesting ideas about how new AI tools might make this more easy to produce. Hence our show live streamed to YouTube Friday, June 2 is OEG Live: Audiobook Versions of OER Textbooks (and AI Implications).
I wanted to jot down some things I have been using and experimenting with for audio production, where AI likely has a place, but is by no means the entire enchilada. So this tale is more about changing out some old tech ways for new ones.
Early on I remember using apps like WireTap pro to snag system audio recorded in Skype calls and a funky little portable iRiver audio recorder for in person sessions. My main audio editing tool of choice was Audacity, and still something I recommend for its features and open source heritage. I not only created a ton of resources for it in the days of teaching DS106 Audio, I used it for pretty much all my media project I did over the last maybe 17, 18 years. Heck Audacity comes up 105 times in my blog (this post will make it hit the magic number, right?)/
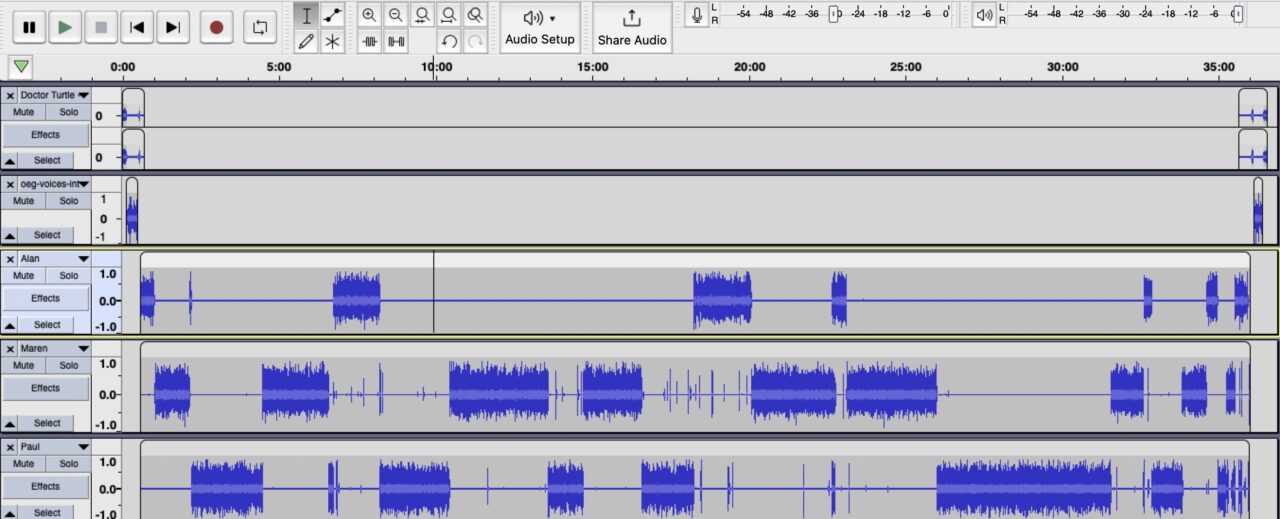
Audacity is what I used for the first two years of editing the OEG Voices podcast. Working in waveforms was pretty much second nature, and I was pretty good at brining in audio recorded in Zoom or Zencastr (where you can separate speaker audio seperate tracks), layer in the multivoice intros and Free Music Archive music tracks.
This was the editing space:
After editing, to generate a transcript i used various tools like Otter.ai and Rev.ai to generate transcripts, and cleaning up required another listening pass. This was time consuming, and for a number of episodes we paid for human transcriptions (~$70/episode), which still needed some cleanup.
Via a Tweet? a Mastodon Post from Paul Privateer I found an interesting tool from Modal Labs offering free transcription using OpenAI Whisper tech. Just by entering “OEG Voices” it bounced back with links for all the episodes. With a click for any episode, and some time for processing, it returned a not bad transcript, that would take some text editing to use, but it gives a taste, that, AI has a useful space for transcribing audio.
Gardner Campbell tuned my into MacWhisper for a nifty means to use that same AI ______ (tool? machine? gizmo? magic blackbox) for audio transcription. You can get a good taste with the free version, the bump for the advanced features might be worth it. There is also Writeout which does transcription via a web interface and translation (“even Klingon”). And likely a kazillion more services, sprouting every day with a free demo and a link to pay for more. Plus other tools for improving audio- my pal Alex Emkerli has been nudging the new Adobe tools.
There is not enough time in a day to try them all, so I rely on trusted recommendations and lucky hunches,
Descript was a ,luck hunch that panned out.
Just by accident, as it seems to do, something I see in passing, in this case boosted by someone in the fediverse, I saw a post that triggered my web spidey sense
I gave Descript a try starting with the first 2023 OEG Podcast with Robert Schuwer. It’s taken some time to hone, but It. Has. Been. A.Game. Changer.
This is a new approach entirely for my audio editing. I upload my speaker audio tracks (no preprocessing needed to convert say .m4a to .wav nor jumping to the Levelator to even out levels), it chugs a few minutes to transcribe. I can apply a “Studio Sound” effect that cleans sound.
But it’s the editing that is different. Transcribing the audio means most (but not all) editing is done via text- removing words, moving sound around is done via looking at text. The audio is tied to the text.
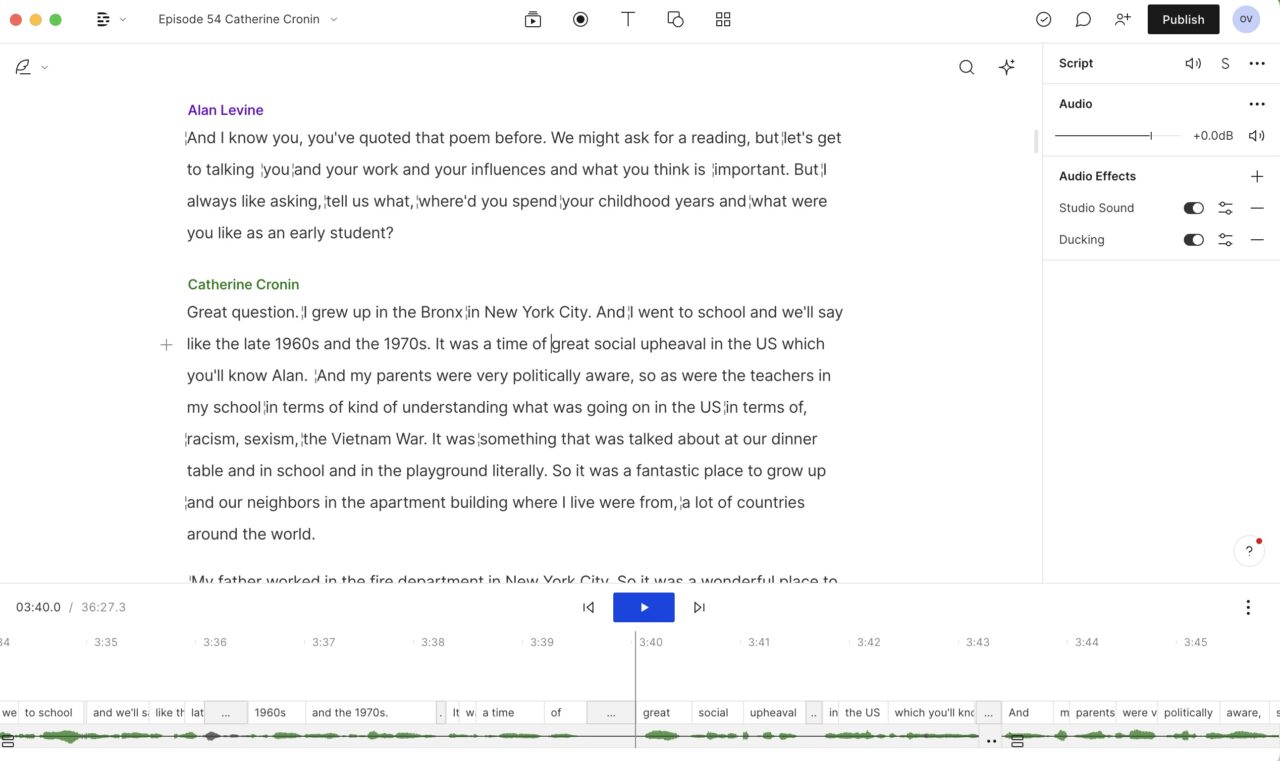
I can move to any point via text or the waveform. It does something where it manages the separate audio tracks as one, so if I delete a word, or nudging something in the timeline (say to increase or decrease the gap above), it modifies all tracks. But if I have a blip in on track, I can jump into the multitrack editor and replace it with a silence gap.
But because I am working with both the transcript and the audio, but I am done editing, both are final. I’m not showing everything, like inserting music, doing fades, invoking ducking. And it took maybe 4 or 5 episodes of fumbling to train myself, but Descript has totally changed my podcast ways (Don’t worry Audacity lovers, I still use it for other edits).
You can get a decent sense of Descript with their free plan, but with the volume of episodes, we went with the $30/month Pro plan for up to 30 transcription hours per month (a multitrack episode of say 4 voices for 50 minutes, incurs 200 minutes of that). That’s much less than paying for decent human transcription (sorry humans, AI just took your grunt work)
And i am maybe at about the 20% level of understanding all Descript does, but that’s enough to keep my pod.
But it’s not just drop something in a magic AI box and out pops a podcast, this is still me, Alan, doing the editing.
Yet, if you like Magic stuff, read on.
Editing podcasts us work enough, but all that work writing up show notes, summaries, creating social media posts, maybe there is some kind of magic.
Well, a coffee meetup in Saskatoon with JR Dingwall dropped me intro Castmagic – “Podcast show notes & content in a click, Upload your MP3, download all your post production content.”
That’s right, just give AI your audio, and let the magic churn.
I gave it a spin for a recent podcast episode of OEG Voices, number 56 with Giovanni Zimotti (- a really interesting Open Educator at University of Iowa, you should check it out. It generates potential titles (none I liked), keywords, highlights, key points, even the text for social media posts (see all it regurgitated).
On one hand, what it achieves and produces is impressive. Woah, is AI taking away my podcast production? Like most things AI, if you stand back from the screen and squint, it looks legit. But up close, I find it missing key elements, and wrongly emphasizing what I know are not the major points. I was there in the conversation.
I’d give it an 7 for effort but I am not ready to drop all I do for some magic AI beans.
I’m not a Debbie Downer in AI, just skeptical. I am more excited here about a tool, Descript, that has really transformed my creation process. It’s not because of AI and frankly I have no idea what AI is really doing in any of these improbable machines, but maybe aided by AI.
This stuff is changing all the time. And likely you out there, random or regular reader, is doing something interesting with AI and audio, so let me know! My human brain seeks more random potential nuerons to connect. And please drop in for our OEG Live show Friday to hash more out for OER, audio, and AI swirling together.
Meanwhile, I have some more Descript-ing to do. You?
I got downsed!
Alan: The new OLDaily’s here! The new OLDaily’’s here!
with apologies to a scene from The Jerk
Felix: Well I wish I could get so excited about nothing.
Alan: Nothing? Are you kidding?! Post 7275, CogDogBlog.! I’m somebody now! Millions of people look at this site every day! This is the kind of spontaneous publicity, you’re name on the web, that makes people. I’m on the web! Things are going to start happening to me now.
I also got Jon Udell interested too…
And from Jon’s post I discovered more exciting features:
Featured Image: Mine! No Silly MidjournalStableConfusingDally stuff.

Thanks to Pat Lockley from who I learned the phrase Gotchya Day, this week I knew to mark April 6 as the day in 2016 that I adopted Felix from the Payson, Arizona Humane Society.
@felixadog celebrates our 2 year “gotchya” day with a visit and donation to Human Society of Central AZ. They all remember “Fix It Felix” nods to @patlockley pic.twitter.com/s1BL9XWLOH
— Alan Levine (@cogdog) April 12, 2018
I had the original photo taken for me by a staff member as I left the facility my “new” dog. I also happen to have the same t-shirt I wore that day (from a trip to Tasmania in 2011). Cori helped with an attempt to redo the photo in 2023.
Until April 2016 as much as I wanted to have a dog, the extensive travel I was doing for work then (a lot of variable length freelance stuff) made it not feasible. Everything changed when I signed on to an 18 month project with Creative Commons (helping craft the design of what has become the Creative Commons Certification).Having solid work mostly from home for that length of time opened the doggy door, as one might say.
Here’s the thing about memory. My internal story was that the week I signed my contract I went down to the Human Society to look for a dog, but since I have contract files (and more reliable, a blog post), I actually started Creative Commons work March 16, 2016. My flickr photos I went to North Carolina 2 days later for an Indie Ed-Tech meetup at Davidson College.
So maybe I pondered the dog idea for a month. I started looking at the Payson Humane Society web page, taking note of what kinds of dogs were available.
I did make my visit to the Humane Society on April 4, 2016. I had met another dog first, some kind of Australian Shepard, named maybe? Jasper. I almost went with him, but thought it wise to just take another for a test drive.
Felix was one in a cage in the front corner, so newly arrived he was not on the site. He was making quite a noisy excited fuss which almost made my ask about the black labs further down, but I asked to see Felix out of the cage.
They let you set outside in a medium sized enclosure to wait to meet a dog. I was sitting on a low curb when they brought Felix out. He sat right next to me and leaned in to my side. That was it, I was chosen.
First pic:

I put down a deposit, as I knew I wanted him, but they encouraged new adopters to go home, check out their home, and come back to claim a dog.
I was back on April 6, no hesitation. After signing and paying the $75 fee, they brought him out to me. Here he came with now what I know as his typical excitement:

And then they offered to take the photo of us together used above.
I remember walking out to the truck and the thought came flying in my head- I have no idea if he;s going to want to jump in a strange vehicle. What do I do if he recoils in fear?
It was no issue. I opened the door, he jumped in faithfully (like he has done 4000 times since), and we drove home. He loves rides. Still.

The next day, April 7, was our first one together. He stuck his head out the rails of the front porch and gave me the iconic look that I have even out to use as my social media icon.
It’s been lots of adventures since, tracked in his own photos (2146 of them!) and tweets. And here we are together 7 years later, living on a rural acreage in Saskatchewan with a Cori in his life plus 2 cats and a world of snow to roll in and rabbits to chase.
April 6, happy Gotchya Day, Felix.
Featured Image: Composite of my own photo from April 6, 2016– Dog Smiles flickr photo by cogdogblog shared under a Creative Commons (BY) license and a redo photo today taken by Cori Saas to be posted later to flickr under a CC0 license.

Not that anyone is keeping score… well I am! For 2023 my double daily habits, the DS106 Daily Create and my Daily Flickr Photo routine have notched another perfect month, bringing both to 90 completions at the end of March, the 90th day of the year.
This follows my streaks for both January and Feburary. Can this blistering pace be maintained? Welcome to March,in like a daily creator and out like a daily photographer, celebrated in the images above of both challenges on the third day of the third month.
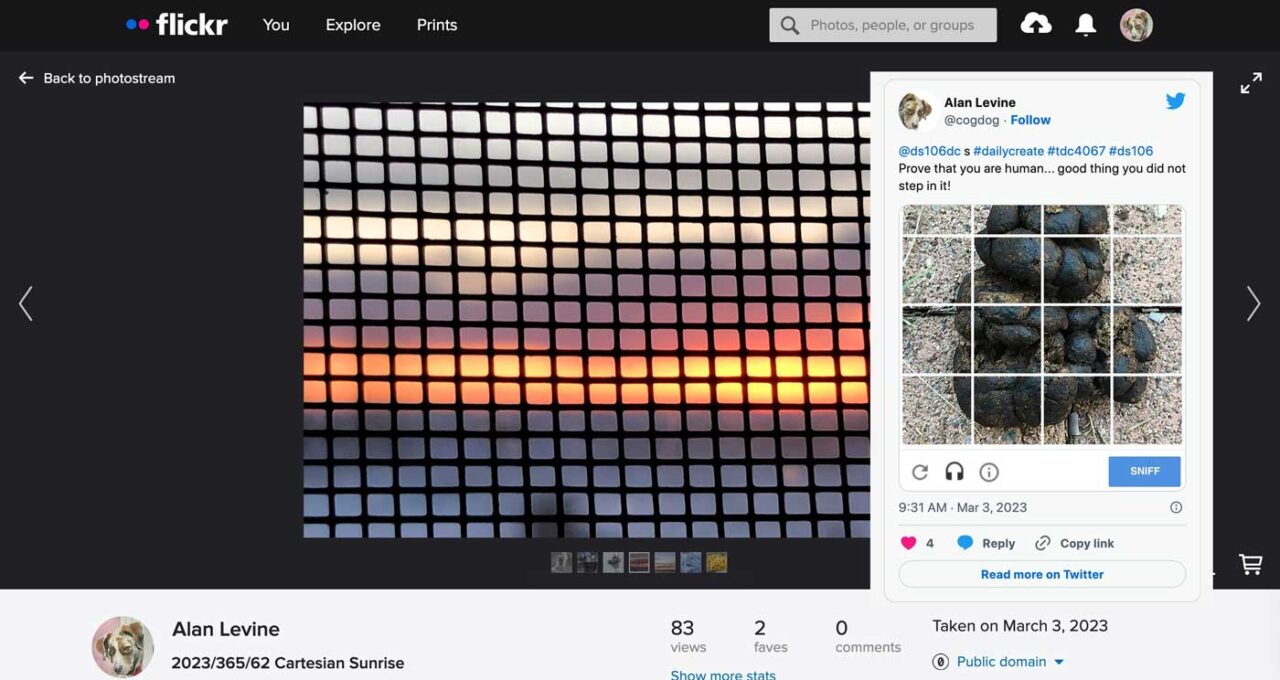
For Flickr on March 3, my daily photo….

And my Daily Create response for March 3 covers my new outlet of “AImocking”.
@ds106dc s #dailycreate #tdc4067 #ds106 Prove that you are human… good thing you did not step in it! pic.twitter.com/cfFlYBaFQj
— Alan Levine (@cogdog) March 3, 2023
Not sure who cares to see what I am doing here, but given the reduction of creativity to what pops out of a black box after entering the 34th version of a prompt… all of these are generated by”CI”– CogDog Irreverence. For this month, maybe just a few more pairs of responses by date.
The Daily Creates this month featured a nifty range of challenges using web generators or randomizers I’ve not seen before. The prescription generator for TDC4075 was one that did on small thing well:
@ds106dc #tdc4075 #ds106 Listen to Dr. Hackenbush, not a hack in the bush at all… pic.twitter.com/WthLPhfhpC
— Alan Levine (@cogdog) March 11, 2023
My photo for the same day? My favorite prescription for making use of those bananas that have been out a bit too long.

The photo for this day was easy to pick as it was the first day we spotted our local fox dad named Watson standing guard outside the den where we know/hope the pups are coming out soon. Spotted out the window with the telephoto lens.

I can only arm wave a connection to the Daily Create for that day (I posted a day late) to “Write (in blue font) a one-liner, wish, wise-crack, proverb (a.k.a Old Dutch Tiles) on a blank tile” Yes, I did a wisecrack about asking ChatGPT to describe themselves in 4 words (“modest” did not make the cut).
@ds106dc #tdc4082 #ds106 Tegeltje-LeegGPT, empty in, empty out. But why not assert your own intelligence? pic.twitter.com/Gs27DvddFw
— Alan Levine (@cogdog) March 19, 2023
Here is a secret…Daily Creates are maybe more fun to make than do. I rather like it when I can pull one from a colleague’s online post like today’s to make a “goofy” face in response to a Mastodon post by @ResearchBuzz (showing off a bit by embedding in the Daily Create but not showing off as I still have not coded the site to accept Mastodon responses) (soon?) (maybe?).
I already had a goofy photo of me following the end of a full Open Education Week doing 14 live webcasts but took the next step to graft on to my head my dog and cat.
@ds106dc #ds106 #dailycreate #tdc4088 A goofy face for @ResearchBuzz and her granddaughter.
— Alan Levine (@cogdog) March 24, 2023
This was me celebrating and energetic after doing 14 live webcasts for #OEweek with my pals Felix and Maggie.
Looking forward to your feedback on the goofiness level. pic.twitter.com/Uw9FLUN1nW
My photo for that same day? Just about as opposite from goofy as on can get- it was a black and white rendering of a foggy morning view of our eastern end of the property, which looks rather spooky.

This habit of monthly recaps is one more self-imposed obligation atop doing these daily acts. They still do as they always have done, gives me a small creative outlet, a chance to see how quickly I can make a response with my own mind, tools, and memory.
I wonder about the DS106 Daily Create, it keeps humming along in its 11the consecutive year but as the leaderboard shows, participating has fallen in 2023 to only 14 participants, of which half have been doing it at like a 90% level.
Is it worth doing?
Hell yeah.
Line me up both daily doubles for April.
Featured Image: Screenshot of my flickr daily photo for March 3, 2023 combined with a screenshot of my tweeted response to the DS106 Daily Create for March 3,2023. Heck I made them, call this licensed CC BY.
What kinds of web footprints are you leaving? Or does it matter since they just blow away? Where do you choose to do your walking?
I am not talking about your data trails, am talking about the trails you make as a contribution for others.
I know my answers, which are just mine, and are not likely anywhere near yours. But with each day of 2023, the web I walked into in November 1993 with the widest sense of wonder (I wonder about when I last wondered about wonder), is fraying away, or being left behind for the commodified mall of platforms. Ot just left as error messages. The 404 web.
I could go darker, I say to my 3 or 4 readers. But. The Wonder is still there, I need to trust in that, and perhaps just extremely unevenly distributed as the past future used to go.
I don’t know why I reached for numerical headings, but am again borrowing your style, Kate Bowles. You see, like the current inevitable technical overlord, my mind is “trained” on stuff (though training is a narrow word for what I think my grey matter CPU does). All I have read and seen is in me, and then I generate something from it. Who ya callin’ Artificial?
There was an online discuss–well thread? blip? where some others I do “follow” and are friends I have been in the same room together, were talking about a certain aviary named technology dying.
My internal storage database went rummaging around for an article a long time ago I read from a rather prominent writer who had driven an interesting stake into the heart of claims that technology “dies”. I remember they had pulled a random page of tools (like implements) from a 1890s?1900s? Sears Catalog, all would be echnologies one would guess are dead. But the author found somewhere in the world, some artisan was still making them.
I could not for the life of me remember the author’s name. I tried the old oracle of knowledge with searches like “writer who found tools from old catalog still in use” and came up empty, just stuff about library catalogs. A few more failed. Is it the search fail or my weak prompts? Because apparently, all future work will be typing prompts into boxes.
Then I remembered I had likely blogged about it. My blog, my outboard brain! And shazam, my own blog search on old catalog tools still being made hits it as a first result- from Feb 1, 2011 Not One Tech Extinction reconnects my neurons! That was Kevin Kelly, a big shot that back then I had as a guest for an NMC online show I did (those footprints of course are wiped out, as is the recording done in old Adobe Connect).
But I did find what I sought, Kelly’s 2006 blog post on Immortal Technologies:
One of my hypothesis is that species of technology, unlike species in biology, do not go extinct. When I really look at supposed extinct species of technology, I find they still survive in some fashion. A close examination of by-gone technologies shows that somewhere on the planet someone is still producing it. A technique or artifact may be rare in the developed world but quite common in the developing world. For instance, Burma is full of ox-cart technology; basketry is ubiquitous in most of Africa; hand spinning still thriving in Bolivia. A technology may be enthusiastically embraced by a heritage-based minority in modern society, if only for traditional satisfaction. Consider the traditional ways of the Amish, or modern tribal communities. Often old technology is obsolete, that is, it is not very ubiquitous or second rate, but it still may be in small-time use, as many old-fashioned ways are.
http://www.kk.org/thetechnium/archives/2006/02/immortal_techno.php
Yep, these days a blog is “enthusiastically embraced by a heritage-based minority in modern society, if only for traditional satisfaction” its posts in small-time use, left as durable footprints on the web, right there sitting where it was 17 years ago.
Someone’s re-share in Mastodon (oh yes boost), maybe it was Roland Tanglao brought a sad note to see from Boris Mann (who I crossed paths with long ago in the Northern Voice Vancouver days)
Boris’s message marked the passing away of Darren Barefoot, who was the co-founder of Northern Voice. In his last days before cancer closed the lights, or maybe it was ahead of time, Darren’s blog left his last web footprint, a post on his own blog/domain, They Were All Splendid.
I will not even taint it by trying to summarize. Read it yourself. I had some memories of seeing his earlier posts (tweeted maybe by Boris or Roland?) or perhaps in flickr photos of Darren’s Splendid things.
His site lists a long set of footprints, his first web site in 1999, but what I remember, his post describing the idea that lead to a survey that led to the first Northern Voice conference in 2005. I became aware of it of course because Brian Lamb blogged about it (more web footprints still visible), and I think reached out to me as I went to Northern Voice for the first of several times in 2006.
I can’t say I knew Darren, I probably met him, but I was there in that era, when nothing was proven and everything possible for the web. I can say I was there.So many things for me came as an outgrowth of Northern Voice, the connections, friendships, photos.
Web footprints that will be there for while.
Sadly, Darren was not the first Northern Voicer to blog their own last post- I remember being astonished/amazed at the web footprint left behind by Derek Miller in 2011, alas also a victim of cancer.
Northern Voice attracted a bunch of digital photography nerds, running informal sessions where people would gather and share/talk about gear, software, and invariably, go out on the Vancouver streets for a photo walk.
That’s where I met Derek. I cannot remember interactions, but that he was always gracious. The thing that is hard to describe about those Northern Voice conferences, is how there was no prestige hierarchy, it was flat, even though it drew upon people from not often overlapping Venn regions- tech nerds, educators, and social activists.
I remember using Derek’s example photos for How a Camera Works, showing visually how aperture shutter speed affected images.
Speaking of web footprints, I forgot Derek’s penmachine.com domain from one of my own Northern Voice talks in 2011- Looking Through the Lens where I tried to make analogies between the functions/settings for photography and learning.
But looking at that old site (broken links, dead flash embeds), are URLs that spark memories- I always liked using Kris Krug’s story that went behind a photo that went beyond viral on flickr. Kris too was like a rock star photographer, yet treated me as a young tech head and just starting in digital photography, as an equal.

I see in my links something stunningly relevant, a post from Kris’s blog:
What we leave behind is our digital footprint (Kris Krug) http://www.kriskrug.com/2011/02/01/what-we-leave-behind-is-our-digital-footprint/
With sad irony, that digital footprint link ends up at a domain for sale sign. Fortunately, ghosts can be summoned from the Wayback Machine.
Our future is being documented by us in our present. Each and everyone of us who has a digital camera, a cellphone, a computer or even a camera phone has the task of creating our living digital history in real time. Our digital landscape has changed drastically from the meaningless dribble that once was in a stream of collective consciousness that is being contributed to by all of us. Collectively everything that we capture is part of our digital footprint that will exist as a living breathing legacy of ourselves online.
…..
The combination of our collective task of documentation and incentive of sharing has joined forces with the thriving Open Source culture. Not only are we inspired to create and then share but we are also infusing the two into spaces, like unconferences and camps, which allow for both situations to transpire. These spaces are open to everyone, sustained by all and owned by none. It only makes perfect sense that our changing interaction with our present state would happen collectively in our own making.
What we leave behind is our digital footprint Kris Krug, Feb 1, 2011
Hello from 2023.
To go back to where this started, mobius strip like, I said “dying” not dead.
I am not contemplating my mountain of web sites as some kind of legacy that matters. Taking care of and preserving my web tracks is not about my last blog post as a goodbye. If anything, it’s perhaps about the first one, and all the ones in between, all of my Pinboard bookmarks (and earlier ones imported from del.icio.us), my flickr photos, the bits and bobs of my archived web sites and ones I have rescued from the dead when others closed shop.
I firmly believe in the web we have woven ourselves (not done by others for us) and the one we care for as individuals. I hate being responsible for breaking any link I have created.
If your followers, likes, and LinkedIn connections are the tracks you care about so be it.
My stuff matters. To me, and I care about that fading dream of the web. Without it, what is there?
There’s always stuff to add after publishing! I wonder if I should comment on my own posts (it helps with the illusion that no one reads me). But sitting in an open tab was Jason Kotke’s marking of his 25th year of leaving footprints
I realize how it sounds, but I’m going to say it anyway because it’s the truth. When I first clapped eyes on the World Wide Web, I fell in love. Here’s how I described the experience in a 2016 post about Halt and Catch Fire:
https://kottke.org/23/03/kottke-is-25-years-old-todayWhen I tell people about the first time I saw the Web, I sheepishly describe it as love at first sight. Logging on that first time, using an early version of NCSA Mosaic with a network login borrowed from my physics advisor, was the only time in my life I have ever seen something so clearly, been sure of anything so completely. It was a like a thunderclap — “the amazing possibility to be able to go anywhere within something that is magnificent and never-ending” — and I just knew this was for me and that it was going to be huge and important. I know how ridiculous this sounds, but the Web is the true love of my life and ever since I’ve been trying to live inside the feeling I had when I first saw it.
I too want to be on the web and “live inside the feeling I had when I first saw it” (back when we had to refer to it as the “World Wide Web” and not simply “the web”).
Featured Image: A combination of two of my own photo, which have their own tracks– Steps into Time flickr photo by cogdogblog shared into the public domain using Creative Commons Public Domain Dedication (CC0) and 2016/366/292 The Web is a Tentative Thing flickr photo by cogdogblog shared into the public domain using Creative Commons Public Domain Dedication (CC0)

Toss together equal portions of luck, fortunate, serendipity, and a sorely needed dose of genuine humanity all went into the mix of the most current episode I am just blessed to click buttons for the OEG Voices Podcast I have been doing for Open Education Global.
This was easily more than just a podcast, this was a moment of sheer positivity that seems more rare these days. I don’t think most of my colleagues truly grasped how powerful a thing we had made possible, simply by offering an invitation to talk, without script or structure.
I’ve already alluded to this episode in my rush of excitement to be part of a series of live, unstructured events for Open Education Week. On the middle day of the week, that just so happened to be International Women’s Day, we had coordinated a conversation with Tetiana Kolesnykova, Director of the Scientific Library at the Ukrainian State University of Science and Technologies, made possible by librarians Paola Corti and Mira Buist-Zhuk (I remain in awe of Mira for her super heroic translation skills to go back and forth between me in English and in Ukrainian for Tetiana).
I had suggested setting this up maybe 2 weeks prior in an email to Paolo who had invited Tetiana who had said she would be there “if she had sufficient electricity.”
Let that one sink in.
Now I am tempted to describe it all over again, but it’s more or less been blogged already by me, and you get as well the full audio of course, transcripts in English and Ukrainian, but mostly, take the time to listen to Tetiana tell how she and her colleagues managed to keep their university mission alive through a war time invasion– just a year ago.
Just to summarize, just three weeks after bombs fell on Dnipro, Tetiana and her colleagues put into operation a crisis plan developed during the pandemic, organized how to provide all kinds of support, including course, library, and research, and she and her staff were at their library just 3 weeks later carrying out this heroic effort.
And it was not like Open Education had to swoop in to offer the OER goodies as a new offering of benevolence; Tetiana and the Scientific library had been practicing, facilitating open access publishing, OER awareness since 2009.
I could not be more honored to just have this time, and in fact, after an hour when I offered and out, Tetiana wanted to keep talking.
After I had published the episode, I drafted an email of thanks to Tetiana, relying on Google Translate to try and turn my words into Ukrainian. She replied (in turn I think by translation):
Hello, dear Alan!
You made me and my family extremely happy people late last night!In my previous life (before the war), I would never have thought that I would be a part of such a wonderful international project. In addition, you created a very cozy and friendly atmosphere in which I, as a guest, felt very comfortable.
At the beginning of the meeting, I was very nervous because: firstly, I didn’t have such experience in recording; secondly, I didn’t have time to prepare; and thirdly, I didn’t know what questions you would ask me.
But your kindness and sincere support, the enormous help of Paola and Mira, as well as the pleasant faces of Marcela and the other participants in your online studio, removed all barriers.Thank you very much, Alan!
You, along with Paola and Mira, gave me wonderful emotions!Alan, my colleagues and I (librarians, teachers, researchers) are also very interested in creating opportunities for collaboration. I would be happy to bring your suggestions to them. I look forward to it.
Thank you very, very much to you, your friends in the studio, your family and everyone who supports Ukrainians in this terrible war.
email from Tetiana Kolesnykova
Your help is invaluable.
I remain firmly convinced that open education is often too focused on the stuff- the resources, licenses, courses, platforms, when really, the most important factors are just being able to have human conversations and connections like these.
Just sit down and say ??????.
Featured Image: My own combination (no artificial intelligence even allowed) of a screenshot of the Ukrainian State University of Science and Technologies web site, a screenshot of the zoom session where we recorded the podcast, and 2011/365/63 On The Air flickr photo by cogdogblog shared under a Creative Commons (BY) license
Against all common wisdom, I have been running an old operating system (10.14.6 Mojave) on my old MacBookPro (2103) to mainly use the photo management software Apple dropped in 2015 (Aperture).
Yes, newer software is out there, and I have access to Lightroom via my Adobe plan I pay through the month for to get PhotoShop, but the Aperture Strategy I have used since honing it in 2009 has just kept working smoothly for me. Especially for adding metadata to all photos and also the (long gone) Connected Flow Flickr Exporter that until recently deftly posted photos, sending titles, tags, captions, said metadata to my flickr and also writing back to Aperture the flickr url.
I did learn recently, from some stellar Flickr support, that the reason many of my photos have gotten mis mapped to the opposite hemisphere is my old software. I was willing to live with my barn photos being located to the Russian village Botsiy.
But the dying has gotten worse. For about the last two weeks, my uploads have been regularly failing like 20% out of a bach with API errors:
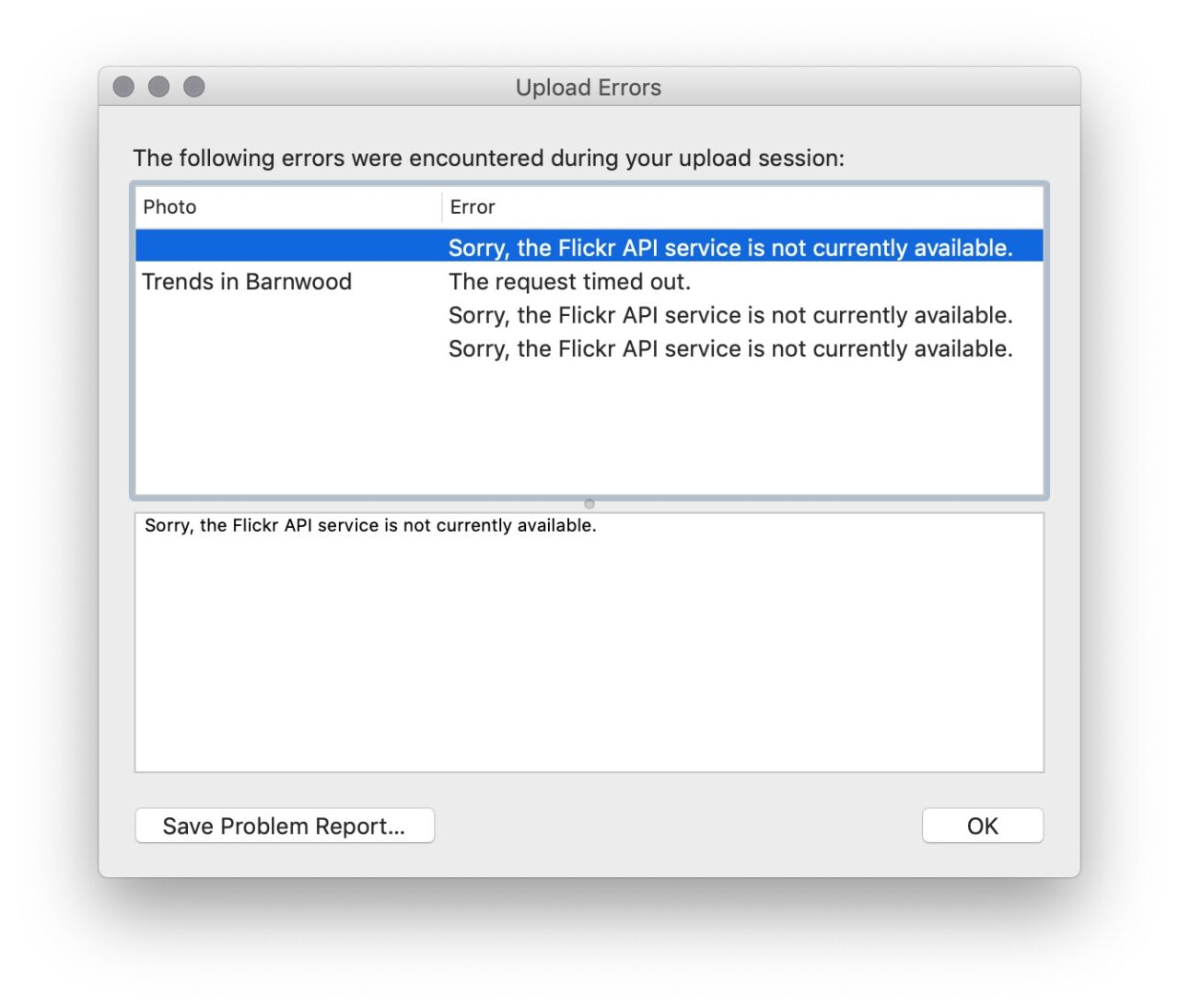
And another plus for the old Flickr Exporter is that it provides tech details in a “problem report” (a log of the comm between Aperture and flickr).
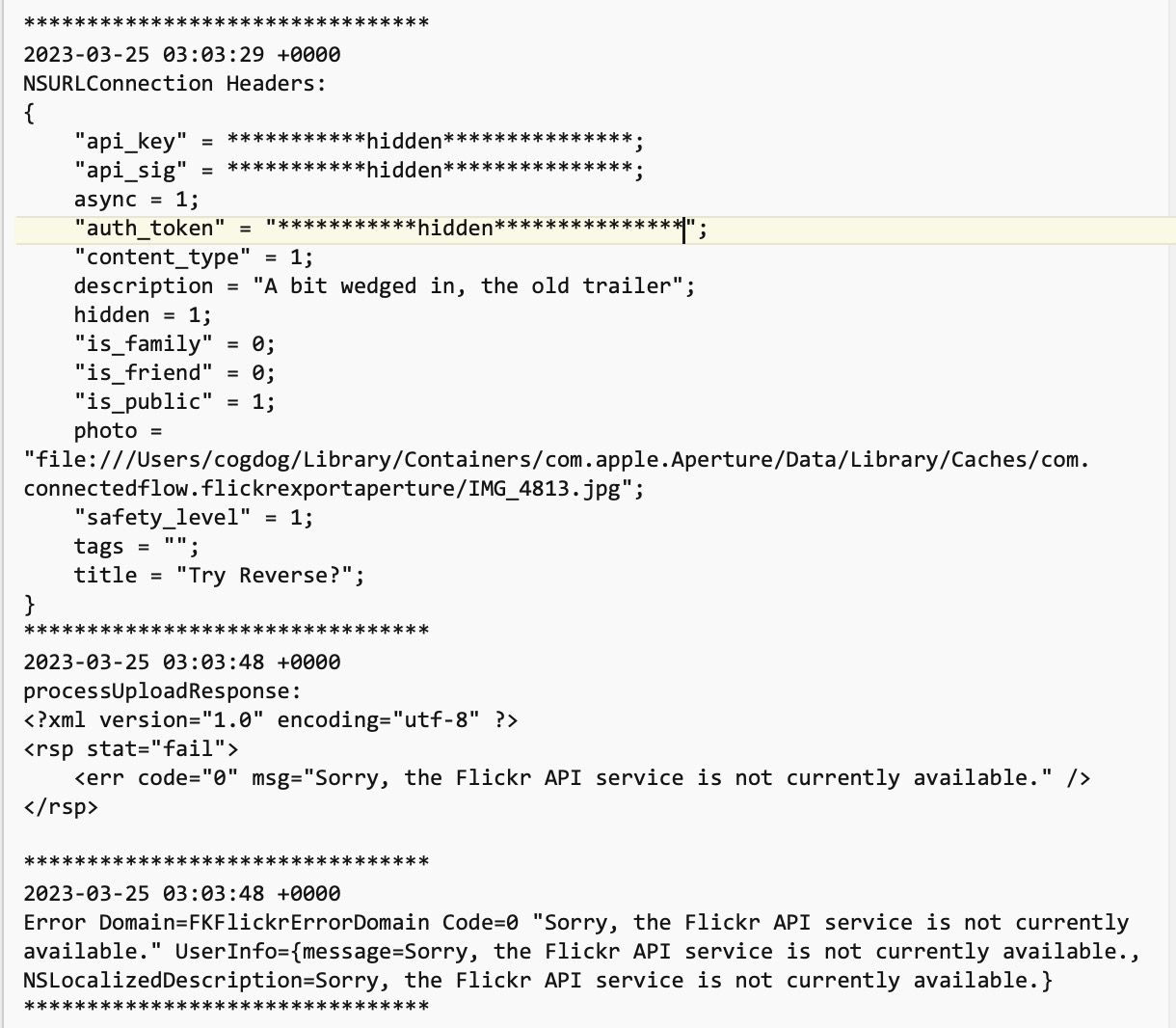
At the same time, I, like many others got a weird email from flickr about impending changes to the Flickr API, they were adding a requirement to include some other data in the transmissions, all played out in a torrid exchange in a flickr forum.
I was invested in this since two of my long running creativity tools (from the days when creativity was not relegated to typing text prompts into an AI box) Pechaflickr and Five Card Flickr Stories depend on the Flickr API to grab random photos based on tags.
I was able to the best of my more hacker than programmer skill set to modify the old phpflickr library that still works. And I managed to make them work in the API change testing window.
All for naught as Flickr announced a day later, in best Emily Litella style– “Never Mind!”

Regardless, I saw other mentions in the forum of others reporting API failures.
The clock is ticking. So I am accepting that its time, 14 years later, to hone a new strategy.
I’m not bothering to try to import my mega Aperture Library into Lightoom. I will leave it as be, but I do have to update my old MacBookPro to some newer mountain named OS (Big Sur I think is as new as I can go). My plan is to leave Aperture running on my even older older MacBookPro, a 2009 dented from a HD killing fall to concrete Just In Case I ever need to re-edit something (not sure when that might ever happen). All my photo originals are on external drives (luckily using Referenced files a long time ago).
This old photo dog needs to learn some new Lightroom tricks.
Thanks Aperture, you’ve been great to me for like 60,000 of my photos (I used the Wayback Machine to find my total in 2009 was about 9000 photos, and look at who I see in the stream there, hiya Scott! BG!).
Onward….
Featured Image: 2015/365/14 What The Lens Sees flickr photo by cogdogblog shared into the public domain using Creative Commons Public Domain Dedication (CC0) with superimposed on the lens a screenshot of my flickr/Aperture error and Pixabay image of Cracks by b0red.

Ain’t that llama a cutie? What is that smile about?
Ah, it’s how this person (a.k.a..me) can stand the fact that someone is making money off of a photo I took and shared on the internets. Doesn’t a license protect me?
Welcome to my unconventional corner of the Creative Commons tent, already explained in 2016:
So counter to thinking some other flavored Creative Commons license will protect me– I have opted to give my store away. Since I never intended to profit from my photos, how can I lose what Inever “moneytized”? I am fine with people making commercial use of my photos, of taking and using without asking. This has been my ongoing experiment for these seven years, to find out how much I will suffer by putting my 70,000 flickr photos in the public domain.
In fact, I have gotten more in return than money… gratitude and stories.
One perk of the Flickr pro account is access to Pixsy, a service that can locate much more reliably places on the internet my photos have appeared. This service is set up to aid in “going after” stolen images, bu my use is mainly to just enjoy seeing sites where my photos have gone to. Sometimes I have gone through just to add to my album of photos that have been reused (283 so far). You know, a little self-flattery.
But it also does provide something I have had to swallow with my giveaway choice described above:
That was he first time I discovered that there are “people” out there who scoop up public domain photos, upload to a stock photo outfit like Alamy, and earn a gazzilion (or 20) bucks. I should be OUTRAGED. But then so should be the schmuck who pays $60 for a photo they could get for free from my flickr.
Recently, I looked at my pixsy updates which reported finding 33 of my photos floating round on Alamy, like heck my goofy llama. You can get it free from flickr or pay Alamy £29.99 to use it on a web site.
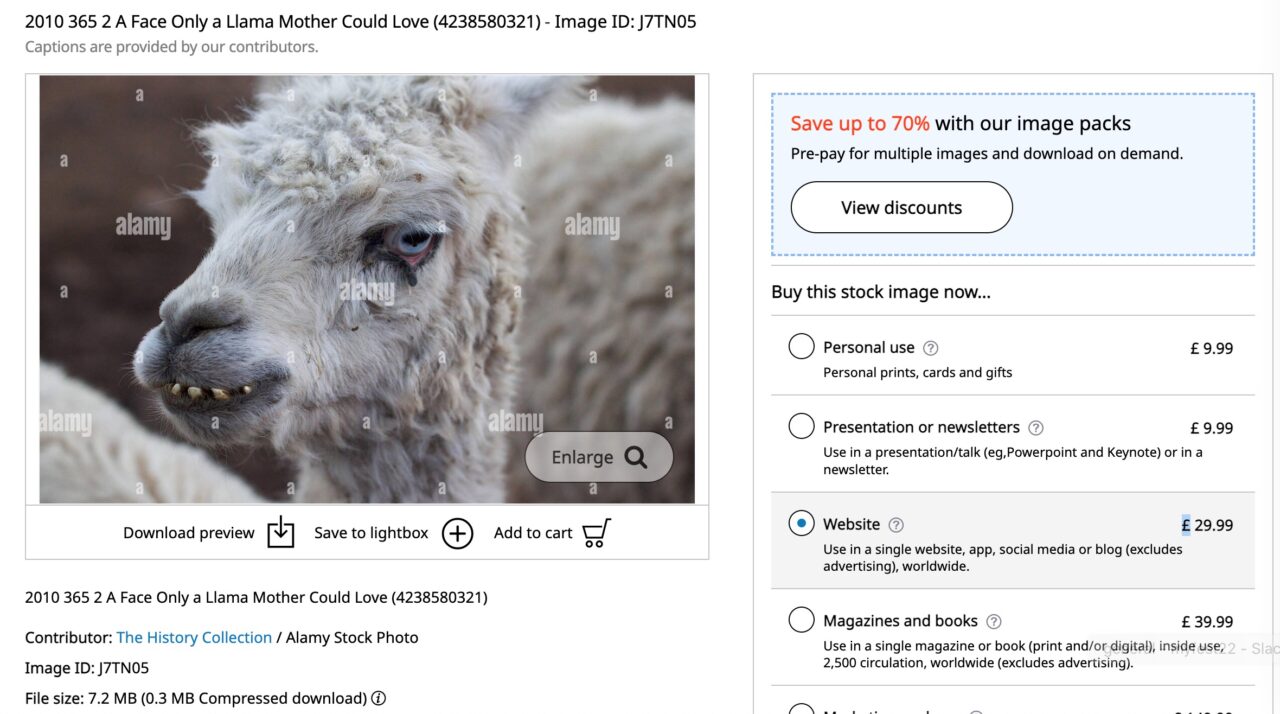
It’s interesting that entity who added my photo kept my original title (the “2010 365” indicates this was one of my daily flickr photos for 2010). Following this, I can play some search gimmicks and find for sale on Alamy:
I could go on… How do I know these are mine? There is no attribution, but it’s easy… I took ’em. But they are easily found in each of my flickr albums for daily photos.
I just have to wonder too about someone how there having to laboriously download my photos and then upload to Alamy, a job of minimal artificial intelligence.
No I am not changing my public domain tune, But in the interest of being curious how this shady game is played, tonight I created my own Alamy account, and uploaded 3 of my own public domain images as they require for “Quality Control”— can I pass muster with my own images?
Here is my pledge- if anyone is goofy enough to pay Alamy for my public domain photos, any proceeds that pile in will be donated to the local Humane Society.
It’s a public domain face a llama mother could love.
Featured Image: Yours for the taking, sans watermark.

Despite the apparent demise of blogs the flat line of the RSS-ograph blips with a pulse from David Kernohan “on chatbots.” FOTA is alive!
Unsure if my comment gets through the gate (a first one generated a critical WordPress error, sorry, David), but I have to at least assert my assertion, as if it blips anywhere in the raging discordant discourse, “Intelligence might be based on pattern recognition as Stephen [Downes] asserts, but it should not be mistaken for intelligence.”
So when David passes a linked reference to the Colossus as the dawn of pattern guessing to decrypt war time messages, my pattern recognition goes to where no GPT can fabricate:

This photo was taken on my own visit to the National Museum of Computing in Bletchley Park, that being a memorable day when Dave and his partner Viv drove me all the way from Bristol where I visited them to Milton Keynes where I spent a week at the Open University.
Maybe a machine could mine the facts from my blog posts and photos, but it would never make connections, the feelings, to the experience of being there that are not digitized or accessible to wholesale scraping. Never.
Or is this my own flailing effort to raise a pitifully tiny flag of I am Human in front of the advancing, inevitable horde of machines? For an image I could have plopped a prompt into a DALL-EMidJourneyStable Diffusion but why, when I can deploy one of my own making?

I could try my best to weave more words around my emerging thought patterns, yes ones that I generate from my own sum of vast experiences. And truly, I could say that I myself, with this nerve network plugged into a 3 pound skull enclosed non-battery powered device, merely have been training 50+ years on written, visual, auditory media,much of which I did not ask explicitly to use, from which I generate through some mystical process, my “own” words? my “own” imagery?
Who better to turn to than Kirby Ferguson to wisely delve into Artificial Creativity?
Stop, watch the whole thing. I mean the whole damn series. I can only yank quotes
Of all Humanity’s technological advances, artificial intelligence is the most morally ambiguous from inception. it has the potential to create either a Utopia or a dystopia. Which reality will we get? Just like everybody else I do not know what’s coming but it seems likely that in coming decades these visions of our imminent demise will seem campy and naive because our imaginings of the future always become campy and naive.
Everything is a Remix Part 4
He takes AI to “court” on three counts, and makes a point that many don’t want to accept, that harvesting all of the “stuff” readily available is maybe not the point of ethics to hang the purveyors. If you buy into his theme that everything is a remix, that means everything is available, as he has done in his video.
But do not take this as suggesting there is a free ticket to just grab content for the classic “because you can” reason. Follow Kirby Ferguson’s statement about all the media he has remixed into his video:
On some videos about AI the big reveal is that this video was actually made by AI. But this video and this series is the opposite. Nothing has been AI except where I cited AI art. This is entirely human made, the words are all mine but they’re merged from the thoughts of countless people. Everything you’ve seen and heard is from real filmmakers and musicians and game developers and other artists. All these thoughts and all this media were remixed by me into something new and yes I did it all without permission.
Everything is a Remix Part 4
The big difference is that this filmmaker provides credits / attribution to he sources. It is very clear what was used. There is no mask of source content or how it was used hidden behind a facade of a commercial purveyor whose very name has washed open with techno-clorox.
Also, lost in the court section is a very valid question-
Training AIs on individual artists work does seem wrong everyone should be able to opt out of all training sets and maybe AIS should simply not train on images from active art communities. Also some company should make an image generator trained on public domain and licensed images which would avoid this Hornet’s Nest entirely. Somebody please do this.
Everything is a Remix Part 4
Why is there no ethical entity out there creating training from public domain or openly licensed materials? Or why does quote/unquote “OPEN” ai DOT com, which already trains its machines on Wikipedia amongst everything else, just create a version limited to truly open content? About the only thing I found was an image generator on hugging face that looks like it does this, but I am not clever enough to make it do anything.
There is a free idea for anyone to pick up.
Finally, Kirby Ferguson ends with a compelling (to me) assertion of the essence of creativity.
AIs will not be dominating creativity because AIs do not innovate. They synthesize what we already know. AI is derivative by design and inventive by chance. Computers can now create but they are not creative. To be creative you need to have some awareness, some understanding of what you’ve done. AIs know nothing whatsoever about the images and words they generate.
Most crucially, AIs have no comprehension of the essence of art, living, AIs don’t know what it’s like to be a child, to grow up, to fall in love, to fall in lust, to be angry, to fight, to forgive, to be a parent, to age, to lose your parents, to get sick, to face death. This is what human expression is about. Art and creativity are bound to living, to feeling. Art is the voice of a person and whenever AI art is anything more than aesthetically pleasing it’s not because of what the AI did it’s because of what a person did.
Art is by humans for humans.
:
Everything is a Remix is a testament to the brilliance and beauty of human creativity. In particular it’s a testament to collective creativity. Human genius is not individual it is shared.
Everything is a Remix Part 4 (emphasis added by me)
Please watch this video! All of them!

But it’s not as clean as just going John Henry and making an untenable slice of human versus machine. Artificial Intelligence “stuff” is a tool, but it’s not “just a tool.” I am reaching back to something I often rely on from Gardner Campbell’s explanation of Marshall McLuhan
“There is no such thing as “just a tool.” McLuhan wisely notes that tools are not inert things to be used by human beings, but extensions of human capabilities that redefine both the tool and the user. A “tooler” results, or perhaps a “tuser” (pronounced “TOO-zer”). I believe those two words are neologisms but I’ll leave the googling as an exercise for the tuser.
The way I used to explain this is my new media classes was to ask students to imagine a hammer lying on the ground and a person standing above the hammer. The person picks up the hammer. What results? The usual answers are something like “a person with a hammer in his or her hand.” I don’t hold much with the elicit-a-wrong-answer-then-spring-the-right-one-on-them school of “Socratic” instruction, but in this case it was irresistible and I tried to make a game of it so folks would feel excited, not tricked. “No!” I would cry. “The result is a HammerHand!”….
http://www.gardnercampbell.net/blog1/doug-engelbart-transcontextualist/
So no “just a tool,” since a HammerHand is something quite different from a hammer or a hand, or a hammer in a hand. Gardner has given me more directly, in email:
I got to that in part because of McLuhan’s famous dictum “the medium is the message.” Most folks appear to think he meant that the medium shapes the message. If you read the piece in which the phrase appears, however, you can see that’s not what he meant. Instead, McLuhan thought of every medium as a message about what we are and desire as human beings. He said the electric light was a message. Every medium should tell us something meta about itself, and something vital about humanity. A medium is not just a channel for transmitting stuff. A medium is also itself a message, a transmission. Can we understand the medium’s message about itself, and thus about us? That’s why the book is called Understanding Media. What is the message these media convey about themselves? and about mediated experience generally?
So with that, I built on Alan Kay (and I think others as well), who said “we shape our tools, and after that our tools shape us,” bringing in the idea of man-computer symbiosis, putting it all within the context of Engelbart’s integrated domain, and then re-reading McLuhan to find a way to express what I took to be something essential about his ideas of human transformation in the development of mediated experience, and I came out with hammerhand.
Gardner Campbell, personal communication
Much of the educator reaction to ChatGPT (which to me is narrow as there is much more we should be wrapping our heads around), so focused on the fear/worry/change factors rather than ” ideas of human transformation in the development of mediated experience.”
Going back to where I started, with David Kernohan’s On Chatbots post, he gives just a short bit at the end to maybe the larger idea of his two, under the heading “A Matter of Semantics”:
I want to close my argument by thinking about the other major strand of artificial intelligence – an associative model that starts (in the modern era) with Vannevar Bush and ends with, well, Google search. The idea of a self-generating set of semantic links – enabling a machine to understand how concepts interrelate – is probably closer to the popular idea of artificial intelligence than toys like ChatGPT.
http://followersoftheapocalyp.se/on-chatbots/
meaning (I think) that the interconnected web of ideas imagined by Bush that influenced Engelbart and actually was instantiated by Tim Berners Lee, is the connectivist idea that the web itself, changing with every new bit linked on to it, offers more potential for making something akin to intelligent than chatbots that are merely regurgitation parts of it in a way that just parody intelligence, not embody it.
So this happened today. It is of no significant to any discussion threading out in the ghosted public square of twitter or the de-aggregated butvibrantcorners of Mastodon, certainly not dead to ne where I will never vention spew pots of (f*** it I cannot call it “Meta” its always Facebook),or the iteration of the America Online is to the real Internet as Linkedin is to ______________… Oh I might have lost my thought completely, as it humanly happens.
Can I get help?
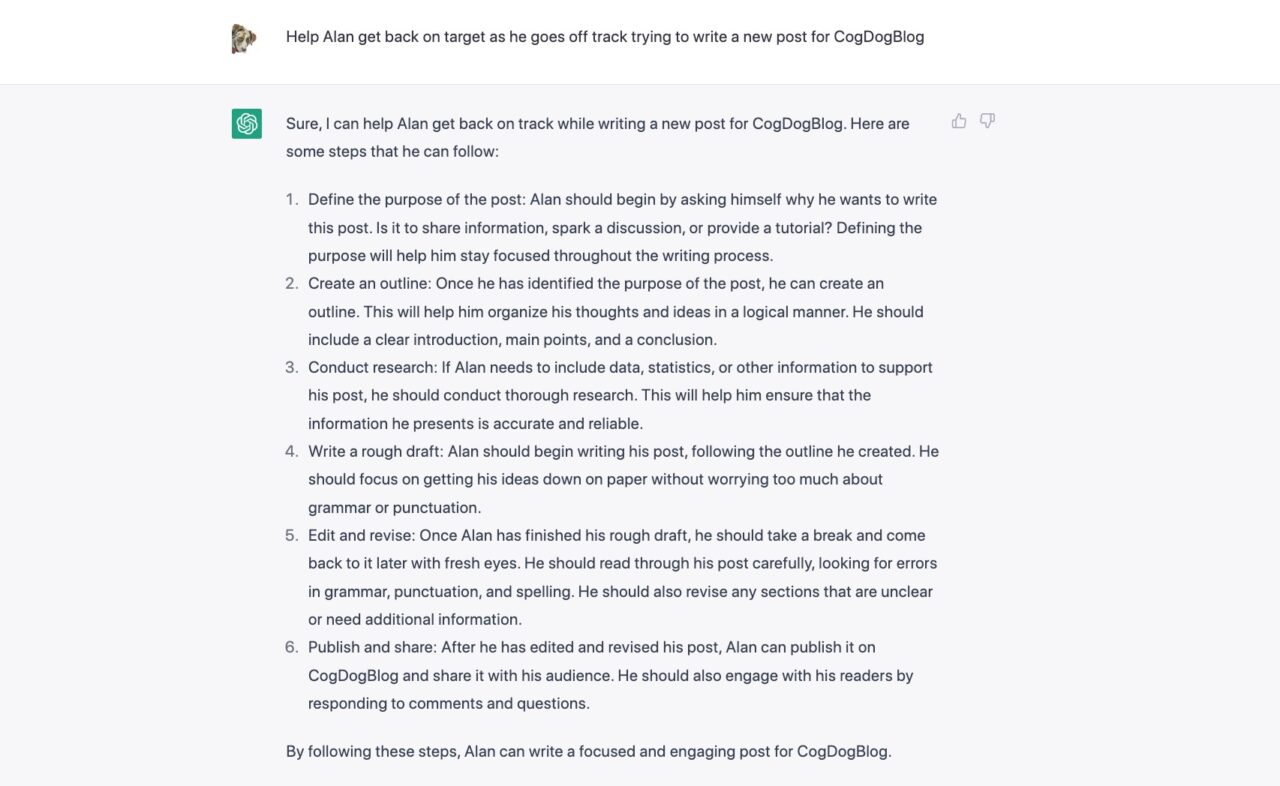
This is what people have their undergarments wadded about? Seriously? I push back
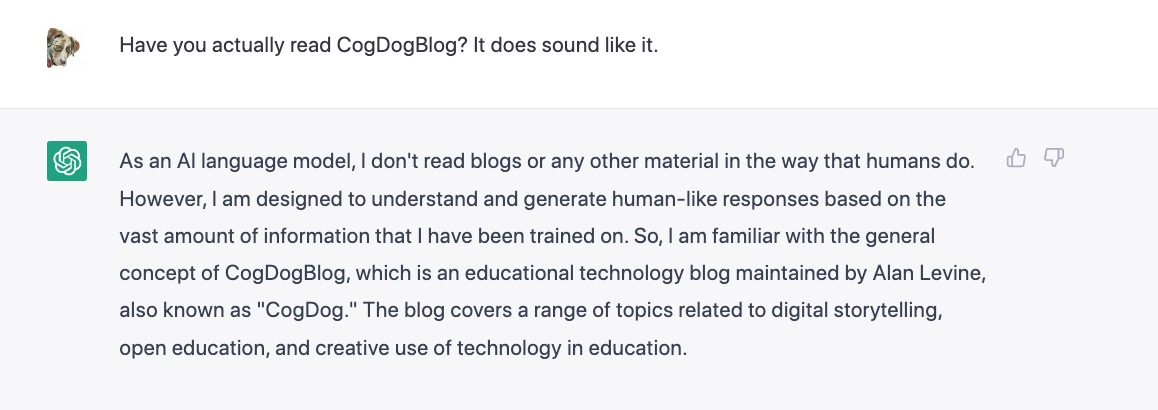
Okay, I am left to my own story making.
Today I sat down to catch up on a few DS106 Daily Creates, it being the very essence of acts of human creativity assisted by tools (using a “TDC HAND”). This was one challenge from a few days ago which in true TDCness, gives a nudge, and opens a door to respond in almost any way.

Lots of ways to run with this, so I just start with the random names generator that suggests possible names from different countries. Cool! I love random stuff and never saw this one. There’s 12 countries listed, each with 10 names. I just decide to be quick and use the first names in the middle row:

Before getting to where / how they meet, I decided I need pictures. Before everyone got wrapped up in Generative text posing as intelligence, there was the phase of all the generative adversarial network (GAN) tools making realistic photos of people and thing that do not exist. If you want a real diversion, see This X Does Not Exist. But I went for the one I remember for generating people, thispersondoesnotexist.com but that now seems gone and only goes to some AI outfit.
But I did find a similarly-URL-ed version at https://this-person-does-not-exist.com/ that was interesting,as there are a few more options to choose from (gender,age range, a few ethnicity options, so I generated 4 non-existent people for Ionut, Lázár, Angel, and Elenor. I imported into Photoshop using one of the Panorama collages which spread them out like photos on a table.
Then I tried to think if where to place these non-existent people. I first reached for a new browser window thinking of some sort of technical image, like a computer circuit board. This is when unexpected-ness happened.
You see I use the Library of Congress Free to Use Browser extension that puts a random public domain image in my screen each time I open a new browser tab. I was fully intending to open an image search, but there, but random chance here was my answer, a road sign for Hanks Coffee Shop, even better, because it was from Bensen Arizona, a place I have been before.

So now it all came together, these people who do not exist, met up for coffee at Hanks in Benson. A bit more Photoshop editing to make a cloud background, superimpose the names of the four, and I was done.
@ds106dc #tdc4081 #ds106 Ionut, Lázár, Angel, and Elenor materialized at https://t.co/DKTTg3iMq5
— Alan Levine (@cogdog) March 19, 2023
Through magic randomness of LOC Random image in a new browser tab, met at Hanks Coffee Shop, in Benson, AZ, which *does* exist, see https://t.co/MDHKBoI7h3 pic.twitter.com/WLDN6ucC5M
“So what?” is certainly a reasonable response. Couldn’t I save time and just type into an image prompt box, “Photos of 4 people displayed under an old time coffee shop sign”? And maybe iterate a few times until it’s “good enough”? Yes, but is making art about the process or the product? Maybe sometimes it is just getting the thing done, turn it in, as they say.
But what is the connection to it? Would an AI remember driving through Benson, AZ on a memorable road trip to camp in the Chiricahua mountains? Would it remember a completely un-related connection from these photos in the Flickr Commons and that there was a call a while ago for examples of galleries of themed images from the commons? And would it then decide, for no productive reason, to search for other Arizona road sign images in the flickr commons, create a gallery, and then share it back?
I’d say, plausibly, eff no. I want to be doing stuff described as “Art is the voice of a person and whenever AI art is anything more than aesthetically pleasing it’s not because of what the AI did it’s because of what a person did.”
I’m not saying at all don’t do AI. And I absolutely intrigued by what it might offer, we have hardly even scratched the surface. But it does not always mean we have to just line up as robot servants to the AI Industrial Complex.
If we lose our ability, interest, to be non stochastically human in our tasks, then we end up being “derivative by design and inventive by chance.”
Never. But I am hoping maybe to see before not too long, another just thinking blip from FOTA.
Featured image: Humanly created and selected, mine

How often do we get to participate in small group open discussions of our practices? I am not talking about blipping in social media. Last, I chose to to be organize/be in 18 of them, and energized more energetic than any zoom webinar.
That week was full on for my organization, Open Education Global with the annual celebration of and awareness raising for Open Education Week.
As it has been done every year since like 2014, OEWeek promotes institutions, organizations, inspired individuals, to plan events/activities during the first year of March that are organized into a single calendar (255 total this year). The goal is to make visible a world wide attention to open education through events and it also collects assets (aka resources, 173 of them this year) to it’s library.
So it’s a completely distributed event. There is always of course too many things to take in, but that’s okay. I’ve tried a few things to encourage people to share back what they experienced in our OEG Connect community, even offering open badges for sharing.
In thinking of some ideas for generating more excitement, connection between events, I naturally fell back to previous experiences, and as often it goes, I draw upon my DS106 experience.
What comes back again and again, is the voice of Jim Groom in that very first year of the open DS106 course and likely around the concept of DS106 radio, or maybe it was just the exuberant days of early twitter as a fresh concept- what Jim described as trying to create a sense of “eventness.” This is when there is a hub of excited energy, be it a group of people in a conference hall lobby, or a hashtag on twitter, that emanates outward, that there was something exciting going on. That others would notice it and say to themselves,”I want to be part of that.”
To me, I find it energizing to do unscripted live broadcasts, be it for DS106 but also later doing it for Virtually Connecting.
So I came up with a crazy idea- to do twice a day live webcasts during Open Education Week. Partly to give updates and highlight what was happening, but more so, to ask people to enter a virtual studio and be more or less like a live radio show. On the web.
My colleagues were very supportive of the idea (as they seem to be for a long list of previous ones) though I sense they did not understand the concept. Likely I had it more in my head than I could put into meeting notes.

So I just did it, I created a web-based show– OEWeek Live! Without writing out all the details few care to read, I plotted a schedule, created a google signup form, sent out requests, and responded with calendar invites. The production was done using Streamyard which provides a studio space for participants; viewers watch on YouTube, but can send comments/questions to the studio, which can be put on screen. The livestream URL becomes the recorded archive, automatically. I really like what you can do during a live stream to switch layouts, put other messages on screen, and anyone in the studio can screen share.
It’s rather refreshing in feel and form than the dreaded wall of zoom bricks.
Okay, enough, blather, on to the conversations.
The full slate was posted in our OEG Connect Community space (a big bonus of Discourse is that event times can can beentered to display in the viewer’s local time). A quick recap (is quick possible with me?)
But the real joy was so many open, in all ways, conversations that happened in the sessions. After people shared projects/activities, we ended up getting into conversations that crossed between what might seem as separate focuses. We got to topics like finding the joy in learning, the ever present hanging cloud of unknown about AI, and also wha emerged maybe Thursday from a tweeted question, a fantastic round of sharing of what gives people hope.
Even as I write this, I am falling short of really describing what these were like. Perhaps you can get a sense from the recordings, all available linked from the main event list, but also as a playlist.
But wait there were more open conversations!
Another element I have added to Open Education Week is doing two recording sessions during the week for the OEG Voices podcast. The open part is extending invitations to any interested in sitting in to listen or participate, keeping seats open for 8-10 extras in the zoom studio. In many ways it’s not much different from the way these podcasts are run year round, but I feel like the idea of having more people present maybe changes the atmosphere?
I aim for all of the OEG Voices podcasts to be conversational, but the topics do revolve of course around the work and interests of guests.
This year included two beyond outstanding sessions:

I honestly have been eager to meet/talk to Delmar Larsen, the dynamo behind LibreTexts for a long time. His human character comes through on cross twitter/OEG Connect exchanges, and even more in this conversation. The excuse was that LibreTexts won 2 OE Awards for Excellence, but what a joy to learn more about Delmar, the origin story of LibreTexts, how he manages to run a company while at the same time teaching as a full professor of Chemistry, and his humble plans of “world domination.”
I did not think it was possible to top that session, but one that we were able to arrange for Wednesday, that in full synchronicity coincided with International Women’s Day, was maybe the most inspiring conversation I have been lucky to be part of:

I was also eagerly waiting to record a podcast about the OE Award for Excellence in Open Resilience that recognized Tetiana Kolesnykova, Director of the Scientific Library at the Ukrainian State University of Science and Technologies for the efforts made just a year ago using open education resources and practices to support education under the war conditions of the Russian invasion of the Ukraine.
My idea to do this emerged maybe twos prior to Open Education week when I reached out to Paola Corti, the SPARC librarian who helped coordinate a stunning collaboration. The phrase “long shot” was in my subject line. Paola responded almost immediately. She volunteered to organize not only the participation of her European Network of Open Education Librarians (ENOEL) colleague Mira Buist-Zhuk, but also to arrange to have Tetiana herself in the conversation “if she has sufficient electricity.”
Read that line again? Look up resilience in my dictionary, and it links to Tetiana.
“Amazing” would be a major understatement for this open conversation, especially heroic was Mira’s deftness and translating between English and Ukrainian.
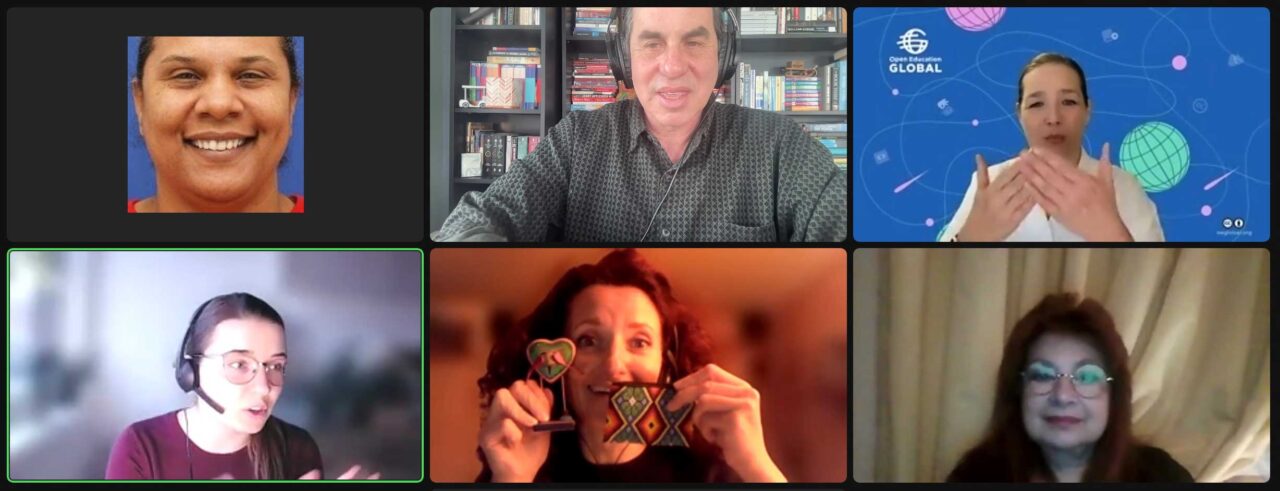
I apologize that you will have to wait for my slow podcast editing to bring you this recording, buti short,know first that Tetiana and her colleagues have been supporting and promoting Open Education at the Ukrainian State University of Science and Technologies since 2009. But beyond that, after the bombing started in Dnipro in February 24, 2022, from their basements and bomb shelters, this University implemented the crisis plan already in place. And while courses were disrupted and students dispersed to safety, Tetiana was back in the library supporting educators just 3 weeks later.
This conversation was __________________ (fill in any synonym for amazing and then emphasize it much more).
Stay tuned to voices.oeglobal.org for both of these episodes.
As synchronicity happens, my long time friend and colleague Todd Conaway invited me to participate in another open conversation session that he runs to support faculty as part of the University of Washington-Bothell’s Teaching & Learning on the Open Web— specifically sessions called Epiphanies where he invite in– oh let him explain it:
At the start of the 2021/2022 school year our learning community decided to invite monthly guest speakers to share “epiphanies” they had experienced in the field of teaching and learning. It turns out that the epiphanies they had helped us have our own.
From December through May, we spend an hour each month with some really remarkable educators. We used a Google dic to write some reflections on the topics discussed and then posed them here on the website. The writings are filled with resources and examples that others can see and share. That is of course the ethos of our learning community. To be open in our work and to share our ideas. Is there anything more useful?
https://uwbopenweb.com/epiphanies/
Todd invited me and more importantly two of my former colleagues from Maricopa Community Colleges, Alisa Cooper (still innovating in teaching at Glendale Community College) and Shelley Rodrigo, currently the University of Arizona. The ask was to share with Todd’s colleagues the story of Shelley’s creation while we all were at Maricopa of the “CyberSalon.”
This happened in a time after the end of a key system wide effort at Maricopa to coordinate faculty and technology staff to brainstorm and collaborate on educational technology (the thing once called Ocotillo, hey look and seem Martin Weller, an old metaphor). Mmissing this means of convening and sharing, Shelley proposed to her network to go outside the system, and meet once a month in a local restaurant or bar that had wireless, and anyone interested would come with their laptops (this was the era pre-smart phones) and “geek out.”
It was one of these sessions that Todd, who worked at a different community college 2 hours north of us, showed up, and eventually became a life-long friend.
This (open, unstructured) conversation seems timely for what Todd has been trying to organize at UWB, as official support for what was a university learning community, has been removed. But they are looking to keep going, unofficially (I hope I am getting the story right).
As much as this (unrecorded) conversation was looking back, it really meant to get at what a participant driven/organized community could do simply by convening (maybe around food?)
Todd agreed in turn to appear on the OEWeek show the day before his session, where he shared this concept. I reminded Todd of his description of the Yavapai College 9x9x25 Writing Challenge (which was replicated in the other formulations, e.g. Write 6×6 active now at Glendale Community College)– as a response to observing that faculty have so few opportunities just to sit down and have open conversations about pedagogy. His concept was to aim for that through networked open reflections in blogs, with a formula geared to provide prompts for regular writing.
Again, it is refreshing to have unstructured open conversations. But the flame is on at University of Washington-Bothell.
But, wait there was one more conversational gathering last week… an impromptu serving of #educoffee.
Here was another version of unstructured gatherings for conversations spawned during the pandemic by another good friend and colleague, Ken Bauer, professor of computer science at Tec de Monterey in Guadalajara. He opened for a long time weekly drop in sessions for local colleagues and students plus distant ones to an open zoom room shared as #educoffee.
Hey, I just remembered that I asked Ken and participants to record a session in 2021 to be used as an OEG Voices podcast:
When Ken posted in Mastodon how busy he has been (his teaching load is unreal) and how much he misses community
I of course could not resist replying with my Google Translated Spanish suggesting an educoffee session. And he opened one up, on Friday of Open Education Week.
Often these are small groups, but what a joy to open to a screen of 9 others in the room! Here is a peek in featuring people from Mexico to Oklahoma to me in Saskatchewan to Windsor and even to the U.K.

Nothing more than an hour of coffee and conversation. How simple is that?
The answer is much more than 14. I am hopeful to continue more of these live “shows” at OEGlobal (my colleagues may be shaking their heads).
And it goes back to Jim’s idea of live energy and “eventness” mattering even more in 2023 with the added noise of social media (which looks like conversations, but it’s a poor substitute) and schedule saturation of structured video meetings.
This photo I used below was a very early live bit when Jim, myself, and Martha Burtis were attending an EDUCAUSE conference in Washington DC, and he went live on DS106 radio for a conversation in his open DS106 class.
Where does all this land for you? Is unstructured conversation time valuable? Or is it madness? I add up 14 and 2 and 2 and get a “hell yes”.
Featured Image: The “madness” of going live for Open Education Week!

Strap in (or hit eject) for a long blog ride. This has been one of those percolating drafts, meaning it has not progressed far from my head. But time is essencing.
As there are a wave of steps to weave together, I am borrowing in all sense of honoring, not stealing, a section convention from Kate Bowles’ blog.
Once again because almost no one cares for making the case of the power of RSS reading, I keep finding more reasons not to buy into the “twitter does it better” theory. I have a set of photography feeds I sometimes skim through at the title level. I cannot even deduce the reason why I got a nibble of curiosity for “The $10 Camera Photographers Are Snapping Up” (Fstoppers).
Curious clicking that was the opener to this whole run.
The author makes a case for the versatility of the old mid 2000s style pocket digital camera, but in this style I loathe in at least a lot of photography sites, asking me to not read, but watch a video of two photographers doing an outing with their $10 cameras. Loathing is because there’s not much skimming one does from content in a video.
The video is well produced, and obviously the two had fun, but I find it all a but more style over substance.
That’s me.
The thing is the video opened a memory stream, as I do not need to find one of these cameras used on eBay, I just need to rummage through my box of camera STUFF.

Memories flood in.
My cameras are a thing I keep track of– by photos. Though it has been 14 years since I wrote of my lineage of film and digital cameras there is only one more not on that list, my current DSLR Canon 7D…assorted iPhones, a few forays trying some vintage cam— I got off track already.
The thing is in 2005 when I plunged into the first DSLR, the Canon Digital Rebel, I saw no direction going back to small pocket cameras.
Shift to 2007 while I was working for the New Media Consortium. Quite a few in that crowd were avid digital photographers. Two colleagues and fellow camera geeks I respect much kept going on and on to me about their little Canon digital cameras. I will call them Phil and Carl for now… well those are their names. These two made a case for what was then rather high image quality from the little cameras (7 MP), but more the affordances of a pocket camera for street photography, and unobtrusive photographer, in lieu of putting a Big Camera in front of your subject.
I took the plunge and bought that PowerShot 800 SD IS. And that was pretty much my main camera for a few years. On a 2008 trip to Japan I could not resist picking up an updated model (IXY 3000IS) that offered maybe twice the resolution and was not even available in the US.
I knew Carl would smile at those specs.
Back in 2002 I was organizing district-wide technology initiatives at the Maricopa Community Colleges. In collaboration with then IT Vice Chancellor Ron Bleed, we organized a series of collaborative events/workshops called the Ocotillo Technology Visioning Forums.
This has much to say about the heady times I was lucky enough to be part of at Maricopa. The rationale of these activities was preparing for a bond election to fund the system, including instructional technology, which as noted there, from the previous planning in 1994 had not included the impact of the world wide web (as the web then was called).
Under the umbrella of bond planning, Ocotillo and Information Technologies Services (ITS) are sponsoring a series of Technology Visioning Forums that will bring to Maricopa a series of distinguished professionals, who will inspire and challenge our thinking about instructional technology and facilities for learning.
For the next X (3? 5?) years, what is the next “web” we might need to address for the future? What is the learning environment of the future look like? What do models of “hybrid” courses mean for planning? What sorts of technologies are we planning for? What do Learning Objects mean for course developers? How do we provide better physical (and virtual) learning environments?
Each Maricopa college will form a team to participate in the process, leading to a collection of outcomes to be further developed at the year-end Ocotillo Retreat.
Ocotillo Technology Visioning, 2002-2003
One of those “distinguished professionals” was a colleague (and friend) of Ron’s from the University of Michigan named Carl Berger, who spent two days in December leading us through discussions guided in his theme of “Back to the Future: After WYSIWYG, What is the Next Killer App?”

The excitement Carl spoke with was infectious, while at the same time backing his ideas with examples, experience, research, and a focus on pedagogy. Amongst the media I found from my old Maricopa MCLI web server archive (all was wiped out after I left in 2006) I found two 320x240px video excerpts from his talk- I patched together to share:
I also found a copy of Carl’s presentation slides!
Here in 2002 he pointed out emerging technologies (just respect this from looking back 21 years) were wireless networking, these brand new tablet devices, learning objects, integrated administrative systems, open learning platforms, research tools, and a vision of a learning platform he called “the Real Processor” explained through a narrative Maria, a professor using a platform that looked LMS-ish but was richer in complexity.
But these forums were not just slidedecks and cheese sandwiches, there was a whole lot of group discussion, brainstorming, and collaboration between faculty, technology staff, and administrators. And, can see it because I found an archive of photos from these events, assembled in a funky Javascript slideshow thing I built in maybe 2000 called the jClicker (I am shocked it even works!):
When I took a leap from Maricopa in 2006 to work with the New Media Consortium, it was a more than pleasant surprise to be at the conferences and connect again with Carl. Here he is gleefully uploading photos he is taking with one of those small cameras at the 2006 NMC Conference in Cleveland.

As I learned Carl was right there from the birth of NMC and was at it’s first conference in 1995. Later, on a visit to his home, he pulled out and gave me a mint condition T-shirt from tha conference (I still have it).

And always Carl was beaming with his excitement about new Apple technology, the latest photo editing software, and always with some new kind of camera. He was active always in the era of NMC’s Second Life period (look! I even found him in the directory as an avatar named Carl Oxberger).
In more image rummaging, I am so happy to find Carl in a photo listening intently to another fantastic friend colleague, Bryan Alexander, here at a 2009 EDUCAUSE ELI Conference.

The photo becomes even more special to me because of the gracious comment of another influential colleagues/mentor, George Brett, who passed away in 2015.
For no one keeping track of the camera stories here, at this time I was using much that small Canon as well as my first iPhone. But the small camera came back in a big way through an unusual device.
Once again,toward my latter years at NMC, I was the beneficiary of a lucky connection. A new colleague named Keene Haywood knew of my interest in camera, and told me about his Austin friends at an outfit called Charmed Labs were developing beta versions of a thing called a “Gigapan“. I was a robot controlled mount that would move a camera methodically through a grid pattern and worked with a stitching type of software to create potentially a GigaPixel panorama image.
I was curious, and Keene hooked me up, and I bought I believe one of the few beta versions of the metallic box rig.

At the time, it could use only the small cameras, and I did a bunch with that first Canon Elph, seen above. It became an object of curiosity in public spaces when people would watch it go through its robot maneuvers, moving a bit, the robot rm clicking the shutter, tilting a bit, and repeating. See it in action:
I recently came across the box where I had stored the rig; it’s been 10 years maybe since I even used it. I assumed that the software that made the images was long gone and after showing it to Cori I said I did not see a need to keep it. “No way!” she said. “That’s part of your photography history, put it on the shelf with your camera collection.”
Out of curiosity I did the Google thing and found out how wrong I was- the software is still out there and the Gigapan site is alive. I even found my own collection of panorama images, all there. I give em a CogDogBlog howl of praise for keeping a web site going 15 years later.
One scene popped out, a panorama image I made on my last day of my 2008 Month in Iceland adventure, when I drove out to see Þingvellir (that place where they were doing democratic forms of government in 930AD).
Typical of most off the highway places I explored while living in Iceland, I saw no people when I got there. So I set up my Gigapan rig to capture a scene.

Then car pulled up! Three American college age students came out. I was shocked when one guy looked at my rig and asked “Is that a GigaPan?”. As it turns out, he had worked at the Carnegie Mellon University where it was first developed.
Now calculate me the odds of that.
Speaking of long odds, I got an email request in 2011 to use the scene I had made that day for use in a book. They wanted the biggest highest resolution possible, I remember doing some hijinks in PhotoShop to generate the format of a TIFF file.
And here is something I know would make Carl smile, a photo stitched together from that little Canon camera was printed in the largest picture atlas ever, a book that is six feet high! That has to be my biggest (literally) credit ever.
I kept in touch with Carl, and it was rewarding to see he had retired and settled in St George, Utah. The last NMC Conference I was part of was the 2010 one at Disneyland, never a place that was on my list of destinations, but conference location picking was not my department. Since I was living then in Northern Arizona I made a decision to skip the air travel and drive to LA, the way out taking the dull Interstate 40 route.
But this made for a scenic backroad return trip, which I had arranged to pass through St. George, at an invitation to stay with Carl. He was eager to show me his latest Lumix camera, but the big part was an outing he set up for us to do some photography together in Zion National Park, one of his favorite places.

What a glorious and ideal a day! Carl was as usual so xcited to share with me his experimentations with HDR photography, later resulting in my buying at Carl’s suggestion a copy of Photomatix Pro software.
Here is an HDR image I later made using that from a photo, which if you read the flickr comments, credits Carl and the software from rendering a fantastic image from originals that were not so great.

I also steered a trip through St George in 2015, on the end of the longway back from a 5 month stint at Thompson Rivers University, in Kamloops BC. I took an even more back way across Nevada (The Extraterrestrial Highway) before pulling up to Carl’s home in St George.
Again, I got a huge warm welcome from him and Shari, we chatted, he showed me his latest geeky toy, a Cardboard VR Camera. If you look at the table, he has more toys out!

Like previous visits together Carl urged me try another photography software, Intensify. So again, I bought software Carl said I should use– and to this day this is maybe the main photo editing tool I turn to whenI cannot tune the image the way I like with my normal controls. I use Intensify usually on 1 or 2 images of my daily photos.
Thanks, again, Carl!
And again, Carl has no limit on his energy and enthusiasm. He suggested a photo outing to the luscious sandstone scenery of Snow Canyon State Park, where we spent hours poking around, climbing sandstone bluffs, taking photos.
Look at this scene– forget Waldo, can you find Carl?

That was eight years ago I visited Carl. Over time, I’d still “see” him active in his flickr stream and we’d “talk” occasionally in comments. I slacked a bit in emailing after I moved to Canada in 2018, but saw some new flickr photos in December. I commented once or twice, asked if he still used his same mac.com email.
Now if you think all of this is written in eulogy like fashion, you are wrong. Well… I got an Instagram message from a mutual colleague who shared that Carl posted in Facebook that he was in hospice with maybe 3 months left to live. But they said he was posting photos a few have come in flickr usual scenery stuff and his little dog, Thor. As my colleague knew I was not on Facebook, they relayed this message from me to Carl.
Hi Carl, I don’t use Facebook but was excited to see a new Flickr photo today of Thor. There’s nothing like the companionship of a dog! I’d give anything to be now walking with you in a Zion canyon, geeking out on cameras, HDR, and hearing your joyful laughter. I regularly use the Intensify CK software you recommended! No need to respond just keep taking photos. With you in spirit, friendship always, Alan
I cannot say enough (well I tried) about the 21 years I have been lucky enough to know and be friends with Carl. They do not even make these kinds of leaders and visionaries any more; ones like Carl who are not in it for ego or spotlight, but because he cares about and loves his work. Carl has been huge influence on me as a mentor, and moreso as a friend.

From little cameras to big panoramas, I am fortunate to have known to the genuine laugh, love of life’ love of teaching, and the big heart of Carl Berger. Keep on clicking the shutter, Carl!
Featured Image: A collage image made from a photo of my old Canon Digital Elph (that Carl inspired me to buy in 2007) That Little Camera flickr photo by cogdogblog shared into the public domain using Creative Commons Public Domain Dedication (CC0), with on the screen a photo of Carl from our 2015 outing — The Eye of Carl Berger flickr photo by cogdogblog shared under a Creative Commons (BY) license plus a screenshot of the Gigapan.com web site.

Flickr does some very fun things for me, and my pink and blue dot loyalty planted in March 2004 remains true. One of the fun things it has done numerous times over the past 6+ years is, without much a recognizable pattern, decides to locate my photos somewhere in rural China and remote regions of Russia.
Case in point, there is an edited photo of a valentine rose posted last week to flickr posted from home here in Saskatchewan but Flickr decides it is a bit farther away. Screen shot version here:

It’s happened so often that I mostly ignore or do not notice, but at least the all seeing eye of Stephen Downes noticed after I shared the photo in Mastodon:
Ah yes, greetings from Botsy (as Wikipedia spells it) “(?????) is a rural locality (a selo) in Dzhidinsky District, Republic of Buryatia, Russia. The population was 550 as of 2010. There are 5 streets.”
Maybe the mis-mapping is some issue with the GPS data captured in my iPhone, but as the EXIF data shows on this photo in flickr, the longitude (around 105 W) is correct.

So if I click the link for flickr’s location in Russia, it reveals 64 of my photos taken around Botsiy!

The clue is in the URL parameters (see why it pays to be curious about URLs?)
https://www.flickr.com/search/?lat=50.46908&lon=105.71585&radius=0.25&has_geo=1&view_all=1
it references longitude as lon=105.71585 which is Longitude EAST. If you flip that value negative to lon=-105.71585 you get some 2386 photos correctly mapped to my area in Saskatchewan.
The question for flickr is- why can you map 2386 photos correctly why do you mess up in the other 64?
I decided to reach out for help in the flickr forums with a post explaining the situation. Alot of user replies came in, suggestions, people tried even reporting my photo and got the same result. Oh, and others confirmed its an old bug. But nothing from Flickr Official.
Someone even noted mine was a duplicate post, I had asked the same question in 2021 (but forgot, there’s nothing that really helps me find my posts in these forums).
The key result I did get was that as a FlickrPro user, if I send via a bug report form, I would get direct service. Where is that? I ended up web searching to find it at https://www.flickrhelp.com/ a site that looks different from the vintage layout of the user forums.
The only thing I did find was via a Contact link to a general request form, which, if you read the top sounds like its more about issues with account access. But I will try anywhere! And BOOM! The response was in maybe 2 hours:
I appreciate you letting us know that you are experiencing an issue with the geolocation mab box on your profile.
from Amanda at Flickr Help
At this time, our engineers have been alerted and are working to resolve the issue.
While I do not have any exact timeframe for when this will be resolved, we are doing everything we can to get everything smoothed out again as quickly as possible.
To which I replied:
It’s not a significant issue for me, I more wanted Flickr to know if this problem. I have seen it happen numerous times over the years; before 2018 when I lived in Arizona, I saw 100s? Of my photos mapped to remote parts of China (my only visits there was to Shanghai and twice to Hong Kong)
Do you need me to find more examples?
Again it really does not bother me, but as a huge fan of Flickr since 2004 I want to help identify any problems.
I went deeper in digging for info on the rose photo that set this off using the Flickr API for the method flickr.photos.getInfo and the photo id 52690089339 the API reveals the wrong location data — longitude="105.715850"
<?xml version="1.0" encoding="utf-8" ?>
<rsp stat="ok">
<photo id="52690089339" secret="05b60de37e" server="65535" farm="66" dateuploaded="1676431124" isfavorite="0" license="9" safety_level="0" rotation="0" originalsecret="323b86829c" originalformat="jpg" views="112" media="photo">
<owner nsid="37996646802@N01" username="cogdogblog" realname="Alan Levine" location="Archydal, Canada" iconserver="7292" iconfarm="8" path_alias="cogdog" />
<title>By Any Color</title>
<description />
<visibility ispublic="1" isfriend="0" isfamily="0" />
<dates posted="1676431124" taken="2023-02-14 16:31:15" takengranularity="0" takenunknown="0" lastupdate="1676471187" />
<permissions permcomment="3" permaddmeta="3" />
<editability cancomment="1" canaddmeta="1" />
<publiceditability cancomment="1" canaddmeta="1" />
<usage candownload="1" canblog="1" canprint="1" canshare="1" />
<comments>0</comments>
<notes />
<people haspeople="0" />
<tags>
<tag id="14901-52690089339-986" author="37996646802@N01" authorname="cogdogblog" raw="rose" machine_tag="0">rose</tag>
</tags>
<location latitude="50.469080" longitude="105.715850" accuracy="16" context="0">
<locality>Botsiy</locality>
<neighbourhood />
<region>Buryatiya Republic</region>
<country>Russia</country>
</location>
<geoperms ispublic="1" iscontact="0" isfriend="0" isfamily="0" />
<urls>
<url type="photopage">https://www.flickr.com/photos/cogdog/52690089339/</url>
</urls>
</photo>
</rsp>
Then I look up the same photo’s exif data via flickr.photos.getExif and the location data looks correct:
<exif tagspace="GPS" tagspaceid="0" tag="GPSLatitudeRef" label="GPS Latitude Ref">
<raw>North</raw>
</exif>
<exif tagspace="GPS" tagspaceid="0" tag="GPSLatitude" label="GPS Latitude">
<raw>50 deg 28' 8.69&quot;</raw>
<clean>50 deg 28' 8.69&quot; N</clean>
</exif>
<exif tagspace="GPS" tagspaceid="0" tag="GPSLongitudeRef" label="GPS Longitude Ref">
<raw>West</raw>
</exif>
<exif tagspace="GPS" tagspaceid="0" tag="GPSLongitude" label="GPS Longitude">
<raw>105 deg 42' 57.06&quot;</raw>
<clean>105 deg 42' 57.06&quot; W</clean>
</exif>
It looks like to me somewhere the conversion from 105 deg 42′ 57.06 West longitude to numerical is fouled. But I have no idea how it works.
My curiosity got to me- was my memory correct? I dug into the Flickr Oragnizr where I can use the bottom options to select my geotagged photos (like 23,000), and then via the Map button I could get a view of all these places in China, Russia, Mongolia where my photos were mis mapped

More than 1100 photos of mine are shown in parts of the world I have never seen. But I can spy the patterns, The locations marked lots south of Irkutsk Russia is where I live now in Saskatchewan. The other area with lots near Henan province in China are ones I took when I lived in Strawberry Arizona. In between these two are photos I took from my early road trips back and forth.
Those ones down in Laos? Some of those were from my times in Guadalajara Mexico.
What we have here is somewhat of a reverse image map of where I have been and roamed over the last few years… let’s see if I can get a comparison map thing going (the location map has to be reversed so the names are backward):


To help flickr I found examples that are explicitly obvious:
The one from Kamloops is telling as others have noticed- my good photo friend from Australia, Michael Coghlan commented in 2017:
You’ve taken pix of this photogenic place before…..but seems Flickr thinks it’s in Mongolia!
https://www.flickr.com/photos/cogdog/33564084071/#comment72157678621828423
I actually don’t care or even want flickr to fix my locations. I like the quirkiness. I just think they should know in case it matters to other people.
As for me? Yes, go ahead and believe I have been up and down the 5 streets of Botsiy, or lived for years in ???, ???, ??, drove through a desert to sea level in ??, ???, ?? south of Jinana, drove through a canyon in Avdzaga, Bulgan, Mongolia… I like the notoriety!
But Flickr, you might want to know what flips the longitude, because it makes a map difference to some folks.
Featured Image: One correctly located!

{kind=link}
{kind=link}